mirror of
https://github.com/HackSoftware/Django-Styleguide.git
synced 2025-07-11 08:22:17 +03:00
1461 lines
46 KiB
Markdown
1461 lines
46 KiB
Markdown

|
||
|
||
---
|
||
|
||
Django styleguide that we use in [HackSoft](https://hacksoft.io).
|
||
|
||
1. We have a [`Styleguide-Example`](https://github.com/HackSoftware/Styleguide-Example) to show most of the styleguide in an actual project.
|
||
1. You can watch Radoslav Georgiev's [Django structure for scale and longevity](https://www.youtube.com/watch?v=yG3ZdxBb1oo) for the philosophy behind the styleguide.
|
||
|
||
**Table of contents:**
|
||
|
||
<!-- toc -->
|
||
|
||
- [Overview](#overview)
|
||
- [Cookie Cutter](#cookie-cutter)
|
||
- [Models](#models)
|
||
* [Base model](#base-model)
|
||
* [Validation - `clean` and `full_clean`](#validation---clean-and-full_clean)
|
||
* [Validation - constraints](#validation---constraints)
|
||
* [Properties](#properties)
|
||
* [Methods](#methods)
|
||
* [Testing](#testing)
|
||
- [Services](#services)
|
||
* [Naming convention](#naming-convention)
|
||
* [Modules](#modules)
|
||
* [Selectors](#selectors)
|
||
* [Testing](#testing-1)
|
||
- [APIs & Serializers](#apis--serializers)
|
||
* [Naming convention](#naming-convention-1)
|
||
* [An example list API](#an-example-list-api)
|
||
+ [Plain](#plain)
|
||
+ [Filters + Pagination](#filters--pagination)
|
||
* [An example detail API](#an-example-detail-api)
|
||
* [An example create API](#an-example-create-api)
|
||
* [An example update API](#an-example-update-api)
|
||
* [Nested serializers](#nested-serializers)
|
||
- [Urls](#urls)
|
||
- [Exception Handling](#exception-handling)
|
||
* [Raising Exceptions in Services / Selectors](#raising-exceptions-in-services--selectors)
|
||
* [Handle Exceptions in APIs](#handle-exceptions-in-apis)
|
||
* [Error formatting](#error-formatting)
|
||
- [Testing](#testing-2)
|
||
* [Naming conventions](#naming-conventions)
|
||
- [Celery](#celery)
|
||
* [Structure](#structure)
|
||
+ [Configuration](#configuration)
|
||
+ [Tasks](#tasks)
|
||
+ [Circular imports between tasks & services](#circular-imports-between-tasks--services)
|
||
* [Periodic Tasks](#periodic-tasks)
|
||
* [Configuration](#configuration-1)
|
||
- [Misc](#misc)
|
||
* [mypy / type annotations](#mypy--type-annotations)
|
||
- [Inspiration](#inspiration)
|
||
|
||
<!-- tocstop -->
|
||
|
||
## Overview
|
||
|
||
**In Django, business logic should live in:**
|
||
|
||
* Model properties (with some exceptions).
|
||
* Model `clean` method for additional validations (with some exceptions).
|
||
* Services - functions, that mostly take care of writing things to the database.
|
||
* Selectors - functions, that mostly take care of fetching things from the database.
|
||
|
||
**In Django, business logic should not live in:**
|
||
|
||
* APIs and Views.
|
||
* Serializers and Forms.
|
||
* Form tags.
|
||
* Model `save` method.
|
||
|
||
**Model properties vs selectors:**
|
||
|
||
* If the property spans multiple relations, it should better be a selector.
|
||
* If the property is non-trivial & can easily cause `N + 1` queries problem, when serialized, it should better be a selector.
|
||
|
||
## Cookie Cutter
|
||
|
||
We recommend starting every new project with some kind of cookiecutter. Having the proper structure from the start pays off.
|
||
|
||
Few examples:
|
||
|
||
* You can use the [`Styleguide-Example`](https://github.com/HackSoftware/Styleguide-Example) project as a starting point.
|
||
* You can also use [`cookiecutter-django`](https://github.com/pydanny/cookiecutter-django) since it has a ton of good stuff inside.
|
||
* Or you can create something that works for your case & turn it into a [cookiecutter](https://cookiecutter.readthedocs.io/en/latest/) project.
|
||
|
||
## Models
|
||
|
||
Models should take care of the data model and not much else.
|
||
|
||
### Base model
|
||
|
||
It's a good idea to define a `BaseModel`, that you can inherit.
|
||
|
||
Usually, fields like `created_at` and `updated_at` are perfect candidates to go into a `BaseModel`.
|
||
|
||
Defining a primary key can also go there. Potential candidate for that is the [`UUIDField`](https://docs.djangoproject.com/en/dev/ref/models/fields/#uuidf)
|
||
|
||
Here's an example `BaseModel`:
|
||
|
||
```python
|
||
from django.db import models
|
||
from django.utils import timezone
|
||
|
||
|
||
class BaseModel(models.Model):
|
||
created_at = models.DateTimeField(db_index=True, default=timezone.now)
|
||
updated_at = models.DateTimeField(auto_now=True)
|
||
|
||
class Meta:
|
||
abstract = True
|
||
```
|
||
|
||
Then, whenever you need a new model, just inherit `BaseModel`:
|
||
|
||
```python
|
||
class SomeModel(BaseModel):
|
||
pass
|
||
```
|
||
|
||
### Validation - `clean` and `full_clean`
|
||
|
||
Lets take a look at an example model:
|
||
|
||
```python
|
||
class Course(BaseModel):
|
||
name = models.CharField(unique=True, max_length=255)
|
||
|
||
start_date = models.DateField()
|
||
end_date = models.DateField()
|
||
|
||
def clean(self):
|
||
if self.start_date >= self.end_date:
|
||
raise ValidationError("End date cannot be before start date")
|
||
```
|
||
|
||
We are defining the model's `clean` method, because we want to make sure we get good data in our database.
|
||
|
||
Now, in order for the `clean` method to be called, someone must call `full_clean` on an instance of our model, before saving.
|
||
|
||
**Our recommendation is to do that in the service, right before calling clean:**
|
||
|
||
```python
|
||
def course_create(*, name: str, start_date: date, end_date: date) -> Course:
|
||
obj = Course(name=name, start_date=start_date, end_date=end_date)
|
||
|
||
obj.full_clean()
|
||
obj.save()
|
||
|
||
return obj
|
||
```
|
||
|
||
This also plays well with Django admin, because the forms used there will trigger `full_clean` on the instance.
|
||
|
||
**We have few general rules of thumb for when to add validation in the model's `clean` method:**
|
||
|
||
1. If we are validating based on multiple, **non-relational fields**, of the model.
|
||
1. If the validation itself is simple enough.
|
||
|
||
**Validation should be moved to the service layer if:**
|
||
|
||
1. The validation logic is more complex.
|
||
1. Spanning relations & fetching additional data is required.
|
||
|
||
> It's OK to have validation both in `clean` and in the service, but we tend to move things in the service, if that's the case.
|
||
|
||
### Validation - constraints
|
||
|
||
As proposed in [this issue](https://github.com/HackSoftware/Django-Styleguide/issues/22), if you can do validation using [Django's constraints](https://docs.djangoproject.com/en/dev/ref/models/constraints/), then you should aim for that.
|
||
|
||
Less code to write, less to code to maintain, the database will take care of the data even if it's being inserted from a different place.
|
||
|
||
Lets look at an example!
|
||
|
||
```python
|
||
class Course(BaseModel):
|
||
name = models.CharField(unique=True, max_length=255)
|
||
|
||
start_date = models.DateField()
|
||
end_date = models.DateField()
|
||
|
||
class Meta:
|
||
constraints = [
|
||
models.CheckConstraint(
|
||
name="start_date_before_end_date",
|
||
check=Q(start_date__lt=F("end_date"))
|
||
)
|
||
]
|
||
```
|
||
|
||
Now, if we try to create new object via `course.save()` or via `Course.objects.create(...)`, we are going to get an `IntegrityError`, rather than a `ValidationError`.
|
||
|
||
This can actually be a downside to the approach, because now, we have to deal with the `IntegrityError`, which does not always have the best error message.
|
||
|
||
The Django's documentation on constraints is quite lean, so you can check the following articles by Adam Johnson, for examples of how to use them:
|
||
|
||
1. [Using Django Check Constraints to Ensure Only One Field Is Set](https://adamj.eu/tech/2020/03/25/django-check-constraints-one-field-set/)
|
||
1. [Django’s Field Choices Don’t Constrain Your Data](https://adamj.eu/tech/2020/01/22/djangos-field-choices-dont-constrain-your-data/)
|
||
1. [Using Django Check Constraints to Prevent Self-Following](https://adamj.eu/tech/2021/02/26/django-check-constraints-prevent-self-following/)
|
||
|
||
### Properties
|
||
|
||
Model properties are great way to quickly access a derived value from a model's instance.
|
||
|
||
For example, lets look at the `has_started` and `has_finished` properties of our `Course` model:
|
||
|
||
```python
|
||
from django.utils import timezone
|
||
from django.core.exceptions import ValidationError
|
||
|
||
|
||
class Course(BaseModel):
|
||
name = models.CharField(unique=True, max_length=255)
|
||
|
||
start_date = models.DateField()
|
||
end_date = models.DateField()
|
||
|
||
def clean(self):
|
||
if self.start_date >= self.end_date:
|
||
raise ValidationError("End date cannot be before start date")
|
||
|
||
@property
|
||
def has_started(self) -> bool:
|
||
now = timezone.now()
|
||
|
||
return self.start_date <= now.date()
|
||
|
||
@property
|
||
def has_finished(self) -> bool:
|
||
now = timezone.now()
|
||
|
||
return self.end_date <= now.date()
|
||
```
|
||
|
||
Those properties are handy, because we can now refer to them in serializers or use them in templates.
|
||
|
||
**We have few general rules of thumb, for when to add properties to the model:**
|
||
|
||
1. If we need a simple derived value, based on **non-relational model fields**, add a `@property` for that.
|
||
1. If the calculation of the derived value is simple enough.
|
||
|
||
**Properties should be something else (service, selector, utility) in the following cases:**
|
||
|
||
1. If we need to span multiple relations or fetch additional data.
|
||
1. If the calculation is more complex.
|
||
|
||
Keep in mind that those rules are vague, because context is quite often important. Use your best judgement!
|
||
|
||
### Methods
|
||
|
||
Model methods are also very powerful tool, that can build on top of properties.
|
||
|
||
Lets see an example with the `is_within(self, x)` method:
|
||
|
||
```python
|
||
from django.core.exceptions import ValidationError
|
||
from django.utils import timezone
|
||
|
||
|
||
class Course(BaseModel):
|
||
name = models.CharField(unique=True, max_length=255)
|
||
|
||
start_date = models.DateField()
|
||
end_date = models.DateField()
|
||
|
||
def clean(self):
|
||
if self.start_date >= self.end_date:
|
||
raise ValidationError("End date cannot be before start date")
|
||
|
||
@property
|
||
def has_started(self) -> bool:
|
||
now = timezone.now()
|
||
|
||
return self.start_date <= now.date()
|
||
|
||
@property
|
||
def has_finished(self) -> bool:
|
||
now = timezone.now()
|
||
|
||
return self.end_date <= now.date()
|
||
|
||
def is_within(self, x: date) -> bool:
|
||
return self.start_date <= x <= self.end_date
|
||
```
|
||
|
||
`is_within` cannot be a property, because it requires an argument. So it's a method instead.
|
||
|
||
Another great way for using methods in models is using them for **attribute setting**, when setting one attribute must always be followed by setting another attribute with a derived value.
|
||
|
||
An example:
|
||
|
||
```python
|
||
from django.utils.crypto import get_random_string
|
||
from django.conf import settings
|
||
from django.utils import timezone
|
||
|
||
|
||
class Token(BaseModel):
|
||
secret = models.CharField(max_length=255, unique=True)
|
||
expiry = models.DateTimeField(blank=True, null=True)
|
||
|
||
def set_new_secret(self):
|
||
now = timezone.now()
|
||
|
||
self.secret = get_random_string(255)
|
||
self.expiry = now + settings.TOKEN_EXPIRY_TIMEDELTA
|
||
|
||
return self
|
||
```
|
||
|
||
Now, we can safely call `set_new_secret`, that'll produce correct values for both `secret` and `expiry`.
|
||
|
||
**We have few general rules of thumb, for when to add methods to the model:**
|
||
|
||
1. If we need a simple derived value, that requires arguments, based on **non-relational model fields**, add a method for that.
|
||
1. If the calculation of the derived value is simple enough.
|
||
1. If setting one attribute always requires setting values to other attributes, use a method for that.
|
||
|
||
**Models should be something else (service, selector, utility) in the following cases:**
|
||
|
||
1. If we need to span multiple relations or fetch additional data.
|
||
1. If the calculation is more complex.
|
||
|
||
Keep in mind that those rules are vague, because context is quite often important. Use your best judgement!
|
||
|
||
### Testing
|
||
|
||
Models need to be tested only if there's something additional to them - like validation, properties or methods.
|
||
|
||
Here's an example:
|
||
|
||
```python
|
||
from datetime import timedelta
|
||
|
||
from django.test import TestCase
|
||
from django.core.exceptions import ValidationError
|
||
from django.utils import timezone
|
||
|
||
from project.some_app.models import Course
|
||
|
||
|
||
class CourseTests(TestCase):
|
||
def test_course_end_date_cannot_be_before_start_date(self):
|
||
start_date = timezone.now()
|
||
end_date = timezone.now() - timedelta(days=1)
|
||
|
||
course = Course(start_date=start_date, end_date=end_date)
|
||
|
||
with self.assertRaises(ValidationError):
|
||
course.full_clean()
|
||
```
|
||
|
||
A few things to note here:
|
||
|
||
1. We assert that a validation error is going to be raised if we call `full_clean`.
|
||
1. **We are not hitting the database at all**, since there's no need for that. This can speed up certain tests.
|
||
|
||
## Services
|
||
|
||
Services are where business logic lives.
|
||
|
||
The service layer speaks the specific domain language of the software, can access the database & other resources & can interact with other parts of your system.
|
||
|
||
Here's a very simple diagram, positioning the service layer in our Django apps:
|
||
|
||
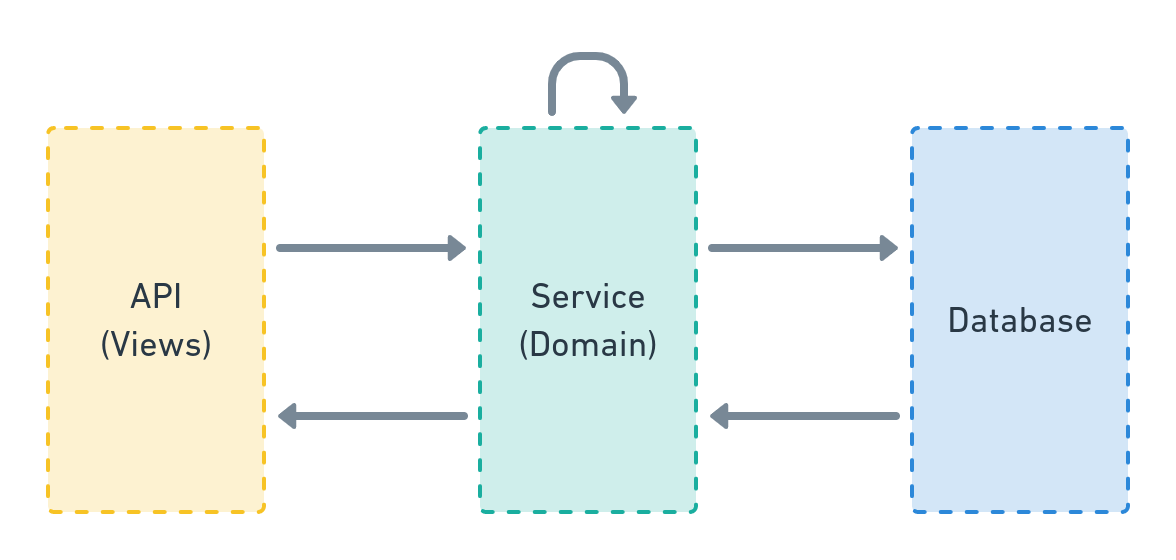
|
||
|
||
A service can be:
|
||
|
||
- A simple function.
|
||
- A class.
|
||
- An entire module.
|
||
- Whatever makes sense in your case.
|
||
|
||
In most cases, a service can be simple function that:
|
||
|
||
- Lives in `<your_app>/services.py` module.
|
||
- Takes keyword-only arguments, unless it requires no or one argument.
|
||
- Is type-annotated (even if you are not using [`mypy`](https://github.com/python/mypy) at the moment).
|
||
- Interacts with the database, other resources & other parts of your system.
|
||
- Does business logic - from simple model creation to complex cross-cutting concerns, to calling external services & tasks.
|
||
|
||
An example service that creates a user:
|
||
|
||
```python
|
||
def user_create(
|
||
*,
|
||
email: str,
|
||
name: str
|
||
) -> User:
|
||
user = User(email=email)
|
||
user.full_clean()
|
||
user.save()
|
||
|
||
profile_create(user=user, name=name)
|
||
confirmation_email_send(user=user)
|
||
|
||
return user
|
||
```
|
||
|
||
As you can see, this service calls 2 other services - `profile_create` and `confirmation_email_send`.
|
||
|
||
In this example, everything related to the user creation is in one place and can be traced.
|
||
|
||
### Naming convention
|
||
|
||
Naming convention depends on your taste. It pays off to have something consistent throughout a project.
|
||
|
||
If we take the example above, our service is named `user_create`. The pattern is - `<entity>_<action>`.
|
||
|
||
This is what we prefer in HackSoft's projects. This seems odd at first, but it has few nice features:
|
||
|
||
* **Namespacing.** It's easy to spot all services starting with `user_` and it's a good idea to put them in a `users.py` module.
|
||
* **Greppability.** Or in other words, if you want to see all actions for a specific entity, just grep for `user_`.
|
||
|
||
### Modules
|
||
|
||
If you have a simple-enough Django app with a bunch of services, they can all live happily in the `service.py` module.
|
||
|
||
But when things get big, you might want to split `services.py` into a folder with sub-modules, depending on the different sub-domains that you are dealing with in your app.
|
||
|
||
For example, lets say we have an `authentication` app, where we have 1 sub-module in our `services` module, that deals with `jwt`, and one sub-module that deals with `oauth`.
|
||
|
||
The structure may look like this:
|
||
|
||
```
|
||
services
|
||
├── __init__.py
|
||
├── jwt.py
|
||
└── oauth.py
|
||
```
|
||
|
||
There are lots of flavors here:
|
||
|
||
- You can do the import-export dance in `services/__init__.py`, so you can import from `project.authentication.services` everywhere else
|
||
- You can create a folder-module, `jwt/__init__.py`, and put the code there.
|
||
- Basically, the structure is up to you. If you feel it's time to restructure and refactor - do so.
|
||
|
||
### Selectors
|
||
|
||
In most of our projects, we distinguish between "Pushing data to the database" and "Pulling data from the database":
|
||
|
||
1. Services take care of the push.
|
||
1. **Selectors take care of the pull.**
|
||
1. Selectors can be viewed as a "sub-layer" to services, that's specialized in fetching data.
|
||
|
||
> If this idea does not resonate well with you, you can just have services for both "kinds" of operations.
|
||
|
||
A selector follows the same rules as a service.
|
||
|
||
For example, in a module `<your_app>/selectors.py`, we can have the following:
|
||
|
||
```python
|
||
def users_list(*, fetched_by: User) -> Iterable[User]:
|
||
user_ids = users_get_visible_for(user=fetched_by)
|
||
|
||
query = Q(id__in=user_ids)
|
||
|
||
return User.objects.filter(query)
|
||
```
|
||
|
||
As you can see, `users_get_visible_for` is another selector.
|
||
|
||
You can return querysets, or lists or whatever makes sense to your specific case.
|
||
|
||
### Testing
|
||
|
||
Since services hold our business logic, they are an ideal candidate for tests.
|
||
|
||
If you decide to cover the service layer with tests, we have few general rules of thumb to follow:
|
||
|
||
1. The tests should cover the business logic behind the services in an exhaustive manner.
|
||
1. The tests should hit the database - creating & reading from it.
|
||
1. The tests should mock async task calls & everything that goes outside the project.
|
||
|
||
When creating the required state for a given test, one can use a combination of:
|
||
|
||
* Fakes (We recommend using [`faker`](https://github.com/joke2k/faker))
|
||
* Other services, to create the required objects.
|
||
* Special test utility & helper methods.
|
||
* Factories (We recommend using [`factory_boy`](https://factoryboy.readthedocs.io/en/latest/orms.html))
|
||
* Plain `Model.objects.create()` calls, if factories are not yet introduced in the project.
|
||
* Usually, whatever suits you better.
|
||
|
||
**Let's take a look at our service from the example:**
|
||
|
||
```python
|
||
from django.contrib.auth.models import User
|
||
from django.core.exceptions import ValidationError
|
||
|
||
from project.payments.selectors import items_get_for_user
|
||
from project.payments.models import Item, Payment
|
||
from project.payments.tasks import payment_charge
|
||
|
||
|
||
def item_buy(
|
||
*,
|
||
item: Item,
|
||
user: User,
|
||
) -> Payment:
|
||
if item in items_get_for_user(user=user):
|
||
raise ValidationError(f'Item {item} already in {user} items.')
|
||
|
||
payment = Payment.objects.create(
|
||
item=item,
|
||
user=user,
|
||
successful=False
|
||
)
|
||
|
||
payment_charge.delay(payment_id=payment.id)
|
||
|
||
return payment
|
||
```
|
||
|
||
The service:
|
||
|
||
* Calls a selector for validation.
|
||
* Creates an object.
|
||
* Delays a task.
|
||
|
||
**Those are our tests:**
|
||
|
||
```python
|
||
from unittest.mock import patch
|
||
|
||
from django.test import TestCase
|
||
from django.contrib.auth.models import User
|
||
from django.core.exceptions import ValidationError
|
||
|
||
from django_styleguide.payments.services import item_buy
|
||
from django_styleguide.payments.models import Payment, Item
|
||
|
||
|
||
class ItemBuyTests(TestCase):
|
||
def setUp(self):
|
||
self.user = User.objects.create_user(username='Test User')
|
||
self.item = Item.objects.create(
|
||
name='Test Item',
|
||
description='Test Item description',
|
||
price=10.15
|
||
)
|
||
|
||
@patch('project.payments.services.items_get_for_user')
|
||
def test_buying_item_that_is_already_bought_fails(self, items_get_for_user_mock):
|
||
"""
|
||
Since we already have tests for `items_get_for_user`,
|
||
we can safely mock it here and give it a proper return value.
|
||
"""
|
||
items_get_for_user_mock.return_value = [self.item]
|
||
|
||
with self.assertRaises(ValidationError):
|
||
item_buy(user=self.user, item=self.item)
|
||
|
||
@patch('project.payments.services.payment_charge.delay')
|
||
def test_buying_item_creates_a_payment_and_calls_charge_task(
|
||
self,
|
||
payment_charge_mock
|
||
):
|
||
self.assertEqual(0, Payment.objects.count())
|
||
|
||
payment = item_buy(user=self.user, item=self.item)
|
||
|
||
self.assertEqual(1, Payment.objects.count())
|
||
self.assertEqual(payment, Payment.objects.first())
|
||
|
||
self.assertFalse(payment.successful)
|
||
|
||
payment_charge_mock.assert_called()
|
||
```
|
||
|
||
|
||
## APIs & Serializers
|
||
|
||
When using services & selectors, all of your APIs should look simple & identical.
|
||
|
||
General rules for an API is:
|
||
|
||
* Do 1 API per operation. For CRUD on a model, this means 4 APIs.
|
||
* Use the most simple `APIView` or `GenericAPIView`
|
||
* Use services / selectors & don't do business logic in your API.
|
||
* Use serializers for fetching objects from params - passed either via `GET` or `POST`
|
||
* Serializer should be nested in the API and be named either `InputSerializer` or `OutputSerializer`
|
||
* `OutputSerializer` can subclass `ModelSerializer`, if needed.
|
||
* `InputSerializer` should always be a plain `Serializer`
|
||
* Reuse serializers as little as possible
|
||
* If you need a nested serializer, use the `inline_serializer` util
|
||
|
||
### Naming convention
|
||
|
||
For our APIs we use the following naming convention: `<Entity><Action>Api`.
|
||
|
||
Here are few examples: `UserCreateApi`, `UserSendResetPasswordApi`, `UserDeactivateApi`, etc.
|
||
|
||
### An example list API
|
||
|
||
#### Plain
|
||
|
||
A dead-simple list API would look like that:
|
||
|
||
```python
|
||
from rest_framework.views import APIView
|
||
from rest_framework import serializers
|
||
from rest_framework.response import Response
|
||
|
||
from styleguide_example.users.selectors import user_list
|
||
from styleguide_example.users.models import BaseUser
|
||
|
||
|
||
class UserListApi(APIView):
|
||
class OutputSerializer(serializers.ModelSerializer):
|
||
class Meta:
|
||
model = BaseUser
|
||
fields = (
|
||
'id',
|
||
'email'
|
||
)
|
||
|
||
def get(self, request):
|
||
users = user_list()
|
||
|
||
data = self.OutputSerializer(users, many=True).data
|
||
|
||
return Response(data)
|
||
```
|
||
|
||
Keep in mind this API is public by default. Authentication is up to you.
|
||
|
||
#### Filters + Pagination
|
||
|
||
At first glance, this is tricky, since our APIs are inheriting the plain `APIView` from DRF, while filtering and pagination are baked into the generic ones:
|
||
|
||
1. [DRF Filtering](https://www.django-rest-framework.org/api-guide/filtering/)
|
||
1. [DRF Pagination](https://www.django-rest-framework.org/api-guide/pagination/)
|
||
|
||
That's why, we take the following approach:
|
||
|
||
1. Selectors take care of the actual filtering.
|
||
1. APIs take care of filter parameter serialization.
|
||
1. APIs take care of pagination.
|
||
|
||
Let's look at the example:
|
||
|
||
```python
|
||
from rest_framework.views import APIView
|
||
from rest_framework import serializers
|
||
|
||
from styleguide_example.api.mixins import ApiErrorsMixin
|
||
from styleguide_example.api.pagination import get_paginated_response, LimitOffsetPagination
|
||
|
||
from styleguide_example.users.selectors import user_list
|
||
from styleguide_example.users.models import BaseUser
|
||
|
||
|
||
class UserListApi(ApiErrorsMixin, APIView):
|
||
class Pagination(LimitOffsetPagination):
|
||
default_limit = 1
|
||
|
||
class FilterSerializer(serializers.Serializer):
|
||
id = serializers.IntegerField(required=False)
|
||
# Important: If we use BooleanField, it will default to False
|
||
is_admin = serializers.NullBooleanField(required=False)
|
||
email = serializers.EmailField(required=False)
|
||
|
||
class OutputSerializer(serializers.ModelSerializer):
|
||
class Meta:
|
||
model = BaseUser
|
||
fields = (
|
||
'id',
|
||
'email',
|
||
'is_admin'
|
||
)
|
||
|
||
def get(self, request):
|
||
# Make sure the filters are valid, if passed
|
||
filters_serializer = self.FilterSerializer(data=request.query_params)
|
||
filters_serializer.is_valid(raise_exception=True)
|
||
|
||
users = user_list(filters=filters_serializer.validated_data)
|
||
|
||
return get_paginated_response(
|
||
pagination_class=self.Pagination,
|
||
serializer_class=self.OutputSerializer,
|
||
queryset=users,
|
||
request=request,
|
||
view=self
|
||
)
|
||
```
|
||
|
||
When we look at the API, we can identify few things:
|
||
|
||
1. There's a `FilterSerializer`, which will take care of the query parameters. If we don't do this here, we'll have to do it elsewhere & DRF serializers are great at this job.
|
||
1. We pass the filters to the `user_list` selector
|
||
1. We use the `get_paginated_response` utility, to return a .. paginated response.
|
||
|
||
Now, let's look at the selector:
|
||
|
||
```python
|
||
import django_filters
|
||
|
||
from styleguide_example.users.models import BaseUser
|
||
|
||
|
||
class BaseUserFilter(django_filters.FilterSet):
|
||
class Meta:
|
||
model = BaseUser
|
||
fields = ('id', 'email', 'is_admin')
|
||
|
||
|
||
def user_list(*, filters=None):
|
||
filters = filters or {}
|
||
|
||
qs = BaseUser.objects.all()
|
||
|
||
return BaseUserFilter(filters, qs).qs
|
||
```
|
||
|
||
As you can see, we are leveraging the powerful [`django-filter`](https://django-filter.readthedocs.io/en/stable/) library.
|
||
|
||
But you can do whatever suits you best here. We have projects, where we implemented our own filtering layer & used it here.
|
||
|
||
The key thing is - **selectors take care of filtering**.
|
||
|
||
Finally, let's look at `get_paginated_response`:
|
||
|
||
```python
|
||
from rest_framework.response import Response
|
||
|
||
|
||
def get_paginated_response(*, pagination_class, serializer_class, queryset, request, view):
|
||
paginator = pagination_class()
|
||
|
||
page = paginator.paginate_queryset(queryset, request, view=view)
|
||
|
||
if page is not None:
|
||
serializer = serializer_class(page, many=True)
|
||
return paginator.get_paginated_response(serializer.data)
|
||
|
||
serializer = serializer_class(queryset, many=True)
|
||
|
||
return Response(data=serializer.data)
|
||
```
|
||
|
||
This is basically a code, extracted from within DRF.
|
||
|
||
Same goes for the `LimitOffsetPagination:
|
||
|
||
```python
|
||
from collections import OrderedDict
|
||
|
||
from rest_framework.pagination import LimitOffsetPagination as _LimitOffsetPagination
|
||
from rest_framework.response import Response
|
||
|
||
|
||
class LimitOffsetPagination(_LimitOffsetPagination):
|
||
default_limit = 10
|
||
max_limit = 50
|
||
|
||
def get_paginated_data(self, data):
|
||
return OrderedDict([
|
||
('limit', self.limit),
|
||
('offset', self.offset),
|
||
('count', self.count),
|
||
('next', self.get_next_link()),
|
||
('previous', self.get_previous_link()),
|
||
('results', data)
|
||
])
|
||
|
||
def get_paginated_response(self, data):
|
||
"""
|
||
We redefine this method in order to return `limit` and `offset`.
|
||
This is used by the frontend to construct the pagination itself.
|
||
"""
|
||
return Response(OrderedDict([
|
||
('limit', self.limit),
|
||
('offset', self.offset),
|
||
('count', self.count),
|
||
('next', self.get_next_link()),
|
||
('previous', self.get_previous_link()),
|
||
('results', data)
|
||
]))
|
||
```
|
||
|
||
What we basically did is reverse-engineered the generic APIs, since pagination should be able to live outside the layers of complexity there.
|
||
|
||
**A possible future implementation should be able to paginate without needing the request / response of the APIView.**
|
||
|
||
You can find the code for the example list API with filters & pagination in the [Styleguide Example](https://github.com/HackSoftware/Styleguide-Example#example-list-api) project.
|
||
|
||
### An example detail API
|
||
|
||
```python
|
||
class CourseDetailApi(SomeAuthenticationMixin, APIView):
|
||
class OutputSerializer(serializers.ModelSerializer):
|
||
class Meta:
|
||
model = Course
|
||
fields = ('id', 'name', 'start_date', 'end_date')
|
||
|
||
def get(self, request, course_id):
|
||
course = get_course(id=course_id)
|
||
|
||
serializer = self.OutputSerializer(course)
|
||
|
||
return Response(serializer.data)
|
||
```
|
||
|
||
### An example create API
|
||
|
||
```python
|
||
class CourseCreateApi(SomeAuthenticationMixin, APIView):
|
||
class InputSerializer(serializers.Serializer):
|
||
name = serializers.CharField()
|
||
start_date = serializers.DateField()
|
||
end_date = serializers.DateField()
|
||
|
||
def post(self, request):
|
||
serializer = self.InputSerializer(data=request.data)
|
||
serializer.is_valid(raise_exception=True)
|
||
|
||
create_course(**serializer.validated_data)
|
||
|
||
return Response(status=status.HTTP_201_CREATED)
|
||
```
|
||
|
||
### An example update API
|
||
|
||
```python
|
||
class CourseUpdateApi(SomeAuthenticationMixin, APIView):
|
||
class InputSerializer(serializers.Serializer):
|
||
name = serializers.CharField(required=False)
|
||
start_date = serializers.DateField(required=False)
|
||
end_date = serializers.DateField(required=False)
|
||
|
||
def post(self, request, course_id):
|
||
serializer = self.InputSerializer(data=request.data)
|
||
serializer.is_valid(raise_exception=True)
|
||
|
||
update_course(course_id=course_id, **serializer.validated_data)
|
||
|
||
return Response(status=status.HTTP_200_OK)
|
||
```
|
||
|
||
### Nested serializers
|
||
|
||
In case you need to use a nested serializer, you can do the following thing:
|
||
|
||
```python
|
||
class Serializer(serializers.Serializer):
|
||
weeks = inline_serializer(many=True, fields={
|
||
'id': serializers.IntegerField(),
|
||
'number': serializers.IntegerField(),
|
||
})
|
||
```
|
||
|
||
The implementation of `inline_serializer` can be found [here](https://github.com/HackSoftware/Styleguide-Example/blob/master/styleguide_example/common/utils.py#L34), in the [Styleguide-Example](https://github.com/HackSoftware/Styleguide-Example) repo.
|
||
|
||
## Urls
|
||
|
||
We usually organize our urls the same way we organize our APIs - 1 url per API, meaning 1 url per action.
|
||
|
||
A general rule of thumb is to split urls from different domains in their own `domain_patterns` list & include from `urlpatterns`.
|
||
|
||
Here's an example with the APIs from above:
|
||
|
||
```python
|
||
from django.urls import path, include
|
||
|
||
from project.education.apis import (
|
||
CourseCreateApi,
|
||
CourseUpdateApi,
|
||
CourseListApi,
|
||
CourseDetailApi,
|
||
CourseSpecificActionApi,
|
||
)
|
||
|
||
|
||
course_patterns = [
|
||
path('', CourseListApi.as_view(), name='list'),
|
||
path('<int:course_id>/', CourseDetailApi.as_view(), name='detail'),
|
||
path('create/', CourseCreateApi.as_view(), name='create'),
|
||
path('<int:course_id>/update/', CourseUpdateApi.as_view(), name='update'),
|
||
path(
|
||
'<int:course_id>/specific-action/',
|
||
CourseSpecificActionApi.as_view(),
|
||
name='specific-action'
|
||
),
|
||
]
|
||
|
||
urlpatterns = [
|
||
path('courses/', include((course_patterns, 'courses'))),
|
||
]
|
||
```
|
||
|
||
**Splitting urls like that can give you the extra flexibility to move separate domain patterns to separate modules**, especially for really big projects, where you'll often have merge conflicts in `urls.py`.
|
||
|
||
## Exception Handling
|
||
|
||
### Raising Exceptions in Services / Selectors
|
||
|
||
Now we have a separation between our HTTP interface & the core logic of our application.
|
||
|
||
To keep this separation of concerns, our services and selectors must not use the `rest_framework.exception` classes because they are bounded with HTTP status codes.
|
||
|
||
Our services and selectors must use one of:
|
||
|
||
* [Python built-in exceptions](https://docs.python.org/3/library/exceptions.html)
|
||
* Exceptions from `django.core.exceptions`
|
||
* Custom exceptions, inheriting from the ones above.
|
||
|
||
Here is a good example of service that performs some validation and raises `django.core.exceptions.ValidationError`:
|
||
|
||
```python
|
||
from django.core.exceptions import ValidationError
|
||
|
||
|
||
def create_topic(*, name: str, course: Course) -> Topic:
|
||
if course.end_date < timezone.now():
|
||
raise ValidationError('You can not create topics for course that has ended.')
|
||
|
||
topic = Topic.objects.create(name=name, course=course)
|
||
|
||
return topic
|
||
```
|
||
|
||
### Handle Exceptions in APIs
|
||
|
||
To transform the exceptions raised in the services or selectors, to a standard HTTP response, you need to catch the exception and raise something that the rest framework understands.
|
||
|
||
The best place to do this is in the `handle_exception` method of the `APIView`. There you can map your Python/Django exception to a DRF exception.
|
||
|
||
By default, the [`handle_exception` method implementation in DRF](https://www.django-rest-framework.org/api-guide/exceptions/#exception-handling-in-rest-framework-views) handles Django's built-in `Http404` and `PermissionDenied` exceptions, thus there is no need for you to handle it by hand.
|
||
|
||
Here is an example:
|
||
|
||
```python
|
||
from rest_framework import exceptions as rest_exceptions
|
||
|
||
from django.core.exceptions import ValidationError
|
||
|
||
|
||
class CourseCreateApi(SomeAuthenticationMixin, APIView):
|
||
expected_exceptions = {
|
||
ValidationError: rest_exceptions.ValidationError
|
||
}
|
||
|
||
class InputSerializer(serializers.Serializer):
|
||
...
|
||
|
||
def post(self, request):
|
||
serializer = self.InputSerializer(data=request.data)
|
||
serializer.is_valid(raise_exception=True)
|
||
|
||
create_course(**serializer.validated_data)
|
||
|
||
return Response(status=status.HTTP_201_CREATED)
|
||
|
||
def handle_exception(self, exc):
|
||
if isinstance(exc, tuple(self.expected_exceptions.keys())):
|
||
drf_exception_class = self.expected_exceptions[exc.__class__]
|
||
drf_exception = drf_exception_class(get_error_message(exc))
|
||
|
||
return super().handle_exception(drf_exception)
|
||
|
||
return super().handle_exception(exc)
|
||
```
|
||
|
||
Here's the implementation of `get_error_message`:
|
||
|
||
```python
|
||
def get_first_matching_attr(obj, *attrs, default=None):
|
||
for attr in attrs:
|
||
if hasattr(obj, attr):
|
||
return getattr(obj, attr)
|
||
|
||
return default
|
||
|
||
|
||
def get_error_message(exc):
|
||
if hasattr(exc, 'message_dict'):
|
||
return exc.message_dict
|
||
error_msg = get_first_matching_attr(exc, 'message', 'messages')
|
||
|
||
if isinstance(error_msg, list):
|
||
error_msg = ', '.join(error_msg)
|
||
|
||
if error_msg is None:
|
||
error_msg = str(exc)
|
||
|
||
return error_msg
|
||
```
|
||
|
||
You can move this code to a mixin and use it in every API to prevent code duplication.
|
||
|
||
We call this `ApiErrorsMixin`. Here's a sample implementation from one of our projects:
|
||
|
||
```python
|
||
from rest_framework import exceptions as rest_exceptions
|
||
|
||
from django.core.exceptions import ValidationError
|
||
|
||
from project.common.utils import get_error_message
|
||
|
||
|
||
class ApiErrorsMixin:
|
||
"""
|
||
Mixin that transforms Django and Python exceptions into rest_framework ones.
|
||
Without the mixin, they return 500 status code which is not desired.
|
||
"""
|
||
expected_exceptions = {
|
||
ValueError: rest_exceptions.ValidationError,
|
||
ValidationError: rest_exceptions.ValidationError,
|
||
PermissionError: rest_exceptions.PermissionDenied
|
||
}
|
||
|
||
def handle_exception(self, exc):
|
||
if isinstance(exc, tuple(self.expected_exceptions.keys())):
|
||
drf_exception_class = self.expected_exceptions[exc.__class__]
|
||
drf_exception = drf_exception_class(get_error_message(exc))
|
||
|
||
return super().handle_exception(drf_exception)
|
||
|
||
return super().handle_exception(exc)
|
||
```
|
||
|
||
Having this mixin in mind, our API can be written like that:
|
||
|
||
```python
|
||
class CourseCreateApi(
|
||
SomeAuthenticationMixin,
|
||
ApiErrorsMixin,
|
||
APIView
|
||
):
|
||
class InputSerializer(serializers.Serializer):
|
||
...
|
||
|
||
def post(self, request):
|
||
serializer = self.InputSerializer(data=request.data)
|
||
serializer.is_valid(raise_exception=True)
|
||
|
||
create_course(**serializer.validated_data)
|
||
|
||
return Response(status=status.HTTP_201_CREATED)
|
||
```
|
||
|
||
All of the code above can be found in [here](https://github.com/HackSoftware/Styleguide-Example/blob/master/styleguide_example/api/mixins.py#L70), in the [Styleguide-Example](https://github.com/HackSoftware/Styleguide-Example) repo.
|
||
|
||
### Error formatting
|
||
|
||
The next step is to generalize the format of the errors we get from our APIs. This will ease the process of displaying errors to the end-user, via JavaScript.
|
||
|
||
If we have a standard serializer and there is an error with one of the fields, the message we get by default looks like this:
|
||
|
||
```python
|
||
{
|
||
"url": [
|
||
"This field is required."
|
||
]
|
||
}
|
||
```
|
||
|
||
If we have a validation error with just a message - `raise ValidationError('Something is wrong.')` - it will look like this:
|
||
|
||
```python
|
||
[
|
||
"some error"
|
||
]
|
||
```
|
||
|
||
Another error format may look like this:
|
||
|
||
```python
|
||
{
|
||
"detail": "Method \"GET\" not allowed."
|
||
}
|
||
```
|
||
|
||
**Those are 3 different ways of formatting for our errors.** What we want to have is a single format, for all errors.
|
||
|
||
Luckily, DRF provides a way for us to give our own custom exception handler, where we can implement the desired formatting: <https://www.django-rest-framework.org/api-guide/exceptions/#custom-exception-handling>
|
||
|
||
In our projects, we format the errors like that:
|
||
|
||
```python
|
||
{
|
||
"errors": [
|
||
{
|
||
"message": "Error message",
|
||
"code": "Some code",
|
||
"field": "field_name"
|
||
},
|
||
{
|
||
"message": "Error message",
|
||
"code": "Some code",
|
||
"field": "nested.field_name"
|
||
},
|
||
]
|
||
}
|
||
```
|
||
|
||
If we raise a `ValidationError`, then the field is optional.
|
||
|
||
In order to achieve that, we implement a custom exception handler:
|
||
|
||
```python
|
||
from rest_framework.views import exception_handler
|
||
|
||
|
||
def exception_errors_format_handler(exc, context):
|
||
response = exception_handler(exc, context)
|
||
|
||
# If an unexpected error occurs (server error, etc.)
|
||
if response is None:
|
||
return response
|
||
|
||
formatter = ErrorsFormatter(exc)
|
||
|
||
response.data = formatter()
|
||
|
||
return response
|
||
```
|
||
|
||
which needs to be added to the `REST_FRAMEWORK` project settings:
|
||
|
||
```python
|
||
REST_FRAMEWORK = {
|
||
'EXCEPTION_HANDLER': 'project.app.handlers.exception_errors_format_handler',
|
||
...
|
||
}
|
||
```
|
||
|
||
**The magic happens in the `ErrorsFormatter` class.**
|
||
|
||
The implementation of that class can be found [here](https://github.com/HackSoftware/Styleguide-Example/blob/master/styleguide_example/api/errors.py), in the [Styleguide-Example](https://github.com/HackSoftware/Styleguide-Example) repo.
|
||
|
||
Combining `ApiErrorsMixin`, the custom exception handler & the errors formatter class, we can have predictable behavior in our APIs, when it comes to errors.
|
||
|
||
**A note:**
|
||
|
||
> We've moved away from this particular way of formatting errors & we'll be updating the styleguide with a more generic approach.
|
||
|
||
## Testing
|
||
|
||
In our Django projects, we split our tests depending on the type of code they represent.
|
||
|
||
Meaning, we generally have tests for models, services, selectors & APIs / views.
|
||
|
||
The file structure usually looks like this:
|
||
|
||
```
|
||
project_name
|
||
├── app_name
|
||
│ ├── __init__.py
|
||
│ └── tests
|
||
│ ├── __init__.py
|
||
│ ├── models
|
||
│ │ └── __init__.py
|
||
│ │ └── test_some_model_name.py
|
||
│ ├── selectors
|
||
│ │ └── __init__.py
|
||
│ │ └── test_some_selector_name.py
|
||
│ └── services
|
||
│ ├── __init__.py
|
||
│ └── test_some_service_name.py
|
||
└── __init__.py
|
||
```
|
||
|
||
### Naming conventions
|
||
|
||
We follow 2 general naming conventions:
|
||
|
||
* The test file names should be `test_the_name_of_the_thing_that_is_tested.py`
|
||
* The test case should be `class TheNameOfTheThingThatIsTestedTests(TestCase):`
|
||
|
||
For example, if we have:
|
||
|
||
```python
|
||
def a_very_neat_service(*args, **kwargs):
|
||
pass
|
||
```
|
||
|
||
We are going to have the following for file name:
|
||
|
||
```
|
||
project_name/app_name/tests/services/test_a_very_neat_service.py
|
||
```
|
||
|
||
And the following for test case:
|
||
|
||
```python
|
||
class AVeryNeatServiceTests(TestCase):
|
||
pass
|
||
```
|
||
|
||
For tests of utility functions, we follow a similar pattern.
|
||
|
||
For example, if we have `project_name/common/utils.py`, then we are going to have `project_name/common/tests/test_utils.py` and place different test cases in that file.
|
||
|
||
If we are to split the `utils.py` module into submodules, the same will happen for the tests:
|
||
|
||
* `project_name/common/utils/files.py`
|
||
* `project_name/common/tests/utils/test_files.py`
|
||
|
||
We try to match the structure of our modules with the structure of their respective tests.
|
||
|
||
## Celery
|
||
|
||
We use [Celery](http://www.celeryproject.org/) for the following general cases:
|
||
|
||
* Communicating with 3rd party services (sending emails, notifications, etc.)
|
||
* Offloading heavier computational tasks outside the HTTP cycle.
|
||
* Periodic tasks (using Celery beat)
|
||
|
||
We try to treat Celery as if it's just another interface to our core logic - meaning - **don't put business logic there.**
|
||
|
||
An example task might look like this:
|
||
|
||
```python
|
||
from celery import shared_task
|
||
|
||
from project.app.services import some_service_name as service
|
||
|
||
|
||
@shared_task
|
||
def some_service_name(*args, **kwargs):
|
||
service(*args, **kwargs)
|
||
```
|
||
This is a task, having the same name as a service, which holds the actual business logic.
|
||
|
||
**Of course, we can have more complex situations**, like a chain or chord of tasks, each of them doing different domain related logic. In that case, it's hard to isolate everything in a service, because we now have dependencies between the tasks.
|
||
|
||
If that happens, we try to expose an interface to our domain & let the tasks work with that interface.
|
||
|
||
One can argue that having an ORM object is an interface by itself, and that's true. Sometimes, you can just update your object from a task & that's OK.
|
||
|
||
But there are times where you need to be strict and don't let tasks do database calls straight from the ORM, but rather, via an exposed interface for that.
|
||
|
||
**More complex scenarios depend on their context. Make sure you are aware of the architecture & the decisions you are making.**
|
||
|
||
### Structure
|
||
|
||
#### Configuration
|
||
|
||
We put Celery configuration in a Django app called `tasks`. The [Celery config](https://docs.celeryproject.org/en/latest/django/first-steps-with-django.html) itself is located in `apps.py`, in `TasksConfig.ready` method.
|
||
|
||
This Django app also holds any additional utilities, related to Celery.
|
||
|
||
Here's an example `project/tasks/apps.py` file:
|
||
|
||
```python
|
||
import os
|
||
|
||
from celery import Celery
|
||
|
||
from django.apps import apps, AppConfig
|
||
from django.conf import settings
|
||
|
||
|
||
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'config.settings.local')
|
||
|
||
|
||
app = Celery('project')
|
||
|
||
|
||
class TasksConfig(AppConfig):
|
||
name = 'project.tasks'
|
||
verbose_name = 'Celery Config'
|
||
|
||
def ready(self):
|
||
app.config_from_object('django.conf:settings', namespace="CELERY")
|
||
app.autodiscover_tasks()
|
||
|
||
|
||
@app.task(bind=True)
|
||
def debug_task(self):
|
||
from celery.utils.log import base_logger
|
||
base_logger = base_logger
|
||
|
||
base_logger.debug('debug message')
|
||
base_logger.info('info message')
|
||
base_logger.warning('warning message')
|
||
base_logger.error('error message')
|
||
base_logger.critical('critical message')
|
||
|
||
print('Request: {0!r}'.format(self.request))
|
||
|
||
return 42
|
||
```
|
||
|
||
#### Tasks
|
||
|
||
Tasks are located in `tasks.py` modules in different apps.
|
||
|
||
We follow the same rules as with everything else (APIs, services, selectors): **if the tasks for a given app grow too big, split them by domain.**
|
||
|
||
Meaning, you can end up with `tasks/domain_a.py` and `tasks/domain_b.py`. All you need to do is import them in `tasks/__init__.py` for Celery to autodiscover them.
|
||
|
||
The general rule of thumb is - split your tasks in a way that'll make sense to you.
|
||
|
||
#### Circular imports between tasks & services
|
||
|
||
In some cases, you need to invoke a task from a service or vice-versa:
|
||
|
||
```python
|
||
# project/app/services.py
|
||
|
||
from project.app.tasks import task_function_1
|
||
|
||
|
||
def service_function_1():
|
||
print('I delay a task!')
|
||
task_function_1.delay()
|
||
|
||
|
||
def service_function_2():
|
||
print('I do not delay a task!')
|
||
```
|
||
|
||
```python
|
||
# project/app/tasks.py
|
||
|
||
from celery import shared_task
|
||
|
||
from project.app.services import service_function_2
|
||
|
||
|
||
@shared_task
|
||
def task_function_1():
|
||
print('I do not call a service!')
|
||
|
||
|
||
@shared_task
|
||
def task_function_2():
|
||
print('I call a service!')
|
||
service_function_2()
|
||
```
|
||
|
||
Unfortunately, this will result in a circular import.
|
||
|
||
What we usually do is we import the service function **inside** the task function:
|
||
|
||
```python
|
||
# project/app/tasks.py
|
||
|
||
from celery import shared_task
|
||
|
||
|
||
@shared_task
|
||
def task_function_1():
|
||
print('I do not call a service!')
|
||
|
||
|
||
@shared_task
|
||
def task_function_2():
|
||
from project.app.services import service_function_2 # <--
|
||
|
||
print('I call a service!')
|
||
service_function_2()
|
||
```
|
||
|
||
* Note: Depending on the case, you may want to import the task function **inside** the service function. This is OK and will still prevent the circular import between service & task functions.
|
||
|
||
### Periodic Tasks
|
||
|
||
Managing periodic tasks is quite important, especially when you have tens or hundreds of them.
|
||
|
||
We use [Celery Beat](https://docs.celeryproject.org/en/latest/userguide/periodic-tasks.html) + `django_celery_beat.schedulers:DatabaseScheduler` + [`django-celery-beat`](https://github.com/celery/django-celery-beat) for our periodic tasks.
|
||
|
||
The extra thing that we do is to have a management command, called `setup_periodic_tasks`, which holds the definition of all periodic tasks within the system. This command is located in the `tasks` app, discussed above.
|
||
|
||
Here's how `project.tasks.management.commands.setup_periodic_tasks.py` looks like:
|
||
|
||
```python
|
||
from django.core.management.base import BaseCommand
|
||
from django.db import transaction
|
||
|
||
from django_celery_beat.models import IntervalSchedule, CrontabSchedule, PeriodicTask
|
||
|
||
from project.app.tasks import some_periodic_task
|
||
|
||
|
||
class Command(BaseCommand):
|
||
help = f"""
|
||
Setup celery beat periodic tasks.
|
||
|
||
Following tasks will be created:
|
||
|
||
- {some_periodic_task.name}
|
||
"""
|
||
|
||
@transaction.atomic
|
||
def handle(self, *args, **kwargs):
|
||
print('Deleting all periodic tasks and schedules...\n')
|
||
|
||
IntervalSchedule.objects.all().delete()
|
||
CrontabSchedule.objects.all().delete()
|
||
PeriodicTask.objects.all().delete()
|
||
|
||
periodic_tasks_data = [
|
||
{
|
||
'task': some_periodic_task
|
||
'name': 'Do some peridoic stuff',
|
||
# https://crontab.guru/#15_*_*_*_*
|
||
'cron': {
|
||
'minute': '15',
|
||
'hour': '*',
|
||
'day_of_week': '*',
|
||
'day_of_month': '*',
|
||
'month_of_year': '*',
|
||
},
|
||
'enabled': True
|
||
},
|
||
]
|
||
|
||
for periodic_task in periodic_tasks_data:
|
||
print(f'Setting up {periodic_task["task"].name}')
|
||
|
||
cron = CrontabSchedule.objects.create(
|
||
**periodic_task['cron']
|
||
)
|
||
|
||
PeriodicTask.objects.create(
|
||
name=periodic_task['name'],
|
||
task=periodic_task['task'].name,
|
||
crontab=cron,
|
||
enabled=periodic_task['enabled']
|
||
)
|
||
```
|
||
|
||
Few key things:
|
||
|
||
* We use this task as part of a deploy procedure.
|
||
* We always put a link to [`crontab.guru`](https://crontab.guru) to explain the cron. Otherwise it's unreadable.
|
||
* Everything is in one place.
|
||
* ⚠️ We use, almost exclusively, a cron schedule. **If you plan on using the other schedule objects, provided by Celery, please read thru their documentation** & the important notes - <https://django-celery-beat.readthedocs.io/en/latest/#example-creating-interval-based-periodic-task> - about pointing to the same schedule object. ⚠️
|
||
|
||
### Configuration
|
||
|
||
Celery is a complex topic, so it's a good idea to invest time reading the documentation & understanding the different configuration options.
|
||
|
||
We constantly do that & find new things or find better approaches to our problems.
|
||
|
||
## Misc
|
||
|
||
### mypy / type annotations
|
||
|
||
About type annotations & using `mypy`, [this tweet](https://twitter.com/queroumavodka/status/1294789817071542272) resonates a lot with our philosophy.
|
||
|
||
We have projects where we enforce `mypy` on CI and are very strict with types.
|
||
|
||
We have projects where types are looser.
|
||
|
||
Context is king here.
|
||
|
||
## Inspiration
|
||
|
||
The way we do Django is inspired by the following things:
|
||
|
||
* The general idea for **separation of concerns**
|
||
* [Boundaries by Gary Bernhardt](https://www.youtube.com/watch?v=yTkzNHF6rMs)
|
||
* Rails service objects
|