95 KiB
| title | teaser | source | menu | ||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Command Line Interface | Download, train and package pipelines, and debug spaCy | spacy/cli |
|
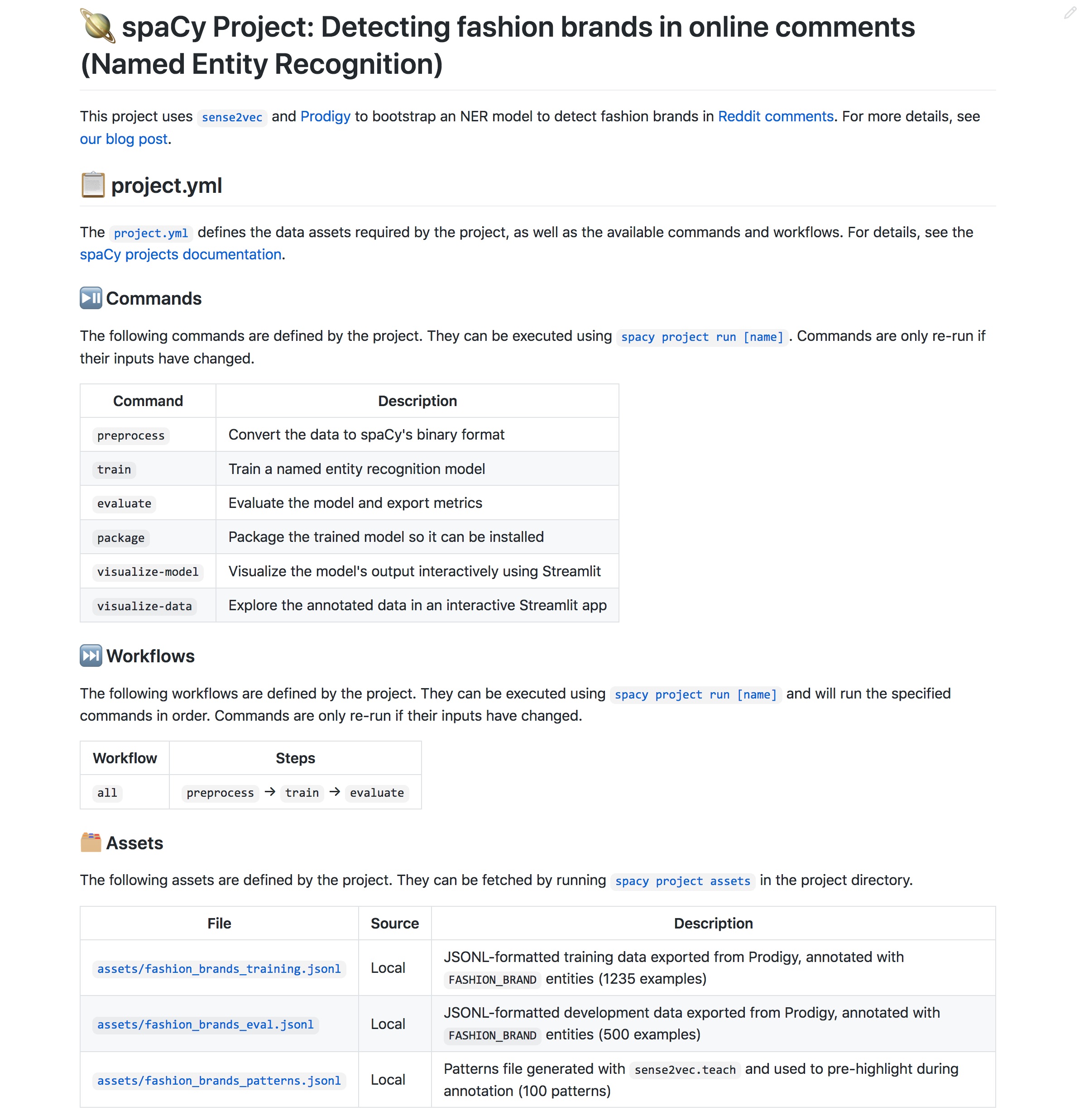
spaCy's CLI provides a range of helpful commands for downloading and training
pipelines, converting data and debugging your config, data and installation. For
a list of available commands, you can type python -m spacy --help. You can
also add the --help flag to any command or subcommand to see the description,
available arguments and usage.
download
Download trained pipelines for spaCy. The downloader finds the
best-matching compatible version and uses pip install to download the Python
package. Direct downloads don't perform any compatibility checks and require the
pipeline name to be specified with its version (e.g. en_core_web_sm-3.0.0).
Downloading best practices
The
downloadcommand is mostly intended as a convenient, interactive wrapper – it performs compatibility checks and prints detailed messages in case things go wrong. It's not recommended to use this command as part of an automated process. If you know which package your project needs, you should consider a direct download via pip, or uploading the package to a local PyPi installation and fetching it straight from there. This will also allow you to add it as a versioned package dependency to your project.
$ python -m spacy download [model] [--direct] [--sdist] [pip_args]
| Name | Description |
|---|---|
model |
Pipeline package name, e.g. en_core_web_sm. |
--direct, -D |
Force direct download of exact package version. |
--sdist, -S 3 |
Download the source package (.tar.gz archive) instead of the default pre-built binary wheel. |
--help, -h |
Show help message and available arguments. |
| pip args 2.1 | Additional installation options to be passed to pip install when installing the pipeline package. For example, --user to install to the user home directory or --no-deps to not install package dependencies. |
| CREATES | The installed pipeline package in your site-packages directory. |
info
Print information about your spaCy installation, trained pipelines and local setup, and generate Markdown-formatted markup to copy-paste into GitHub issues.
$ python -m spacy info [--markdown] [--silent] [--exclude]
Example
$ python -m spacy info en_core_web_lg --markdown
$ python -m spacy info [model] [--markdown] [--silent] [--exclude]
| Name | Description |
|---|---|
model |
A trained pipeline, i.e. package name or path (optional). |
--markdown, -md |
Print information as Markdown. |
--silent, -s 2.0.12 |
Don't print anything, just return the values. |
--exclude, -e |
Comma-separated keys to exclude from the print-out. Defaults to "labels". |
--help, -h |
Show help message and available arguments. |
| PRINTS | Information about your spaCy installation. |
validate
Find all trained pipeline packages installed in the current environment and
check whether they are compatible with the currently installed version of spaCy.
Should be run after upgrading spaCy via pip install -U spacy to ensure that
all installed packages can be used with the new version. It will show a list of
packages and their installed versions. If any package is out of date, the latest
compatible versions and command for updating are shown.
Automated validation
You can also use the
validatecommand as part of your build process or test suite, to ensure all packages are up to date before proceeding. If incompatible packages are found, it will return1.
$ python -m spacy validate
| Name | Description |
|---|---|
| PRINTS | Details about the compatibility of your installed pipeline packages. |
init
The spacy init CLI includes helpful commands for initializing training config
files and pipeline directories.
init config
Initialize and save a config.cfg file using the
recommended settings for your use case. It works just like the
quickstart widget, only that it also auto-fills
all default values and exports a training-ready
config. The settings you specify will impact the suggested model architectures
and pipeline setup, as well as the hyperparameters. You can also adjust and
customize those settings in your config file later.
Example
$ python -m spacy init config config.cfg --lang en --pipeline ner,textcat --optimize accuracy
$ python -m spacy init config [output_file] [--lang] [--pipeline] [--optimize] [--gpu] [--pretraining] [--force]
| Name | Description |
|---|---|
output_file |
Path to output .cfg file or - to write the config to stdout (so you can pipe it forward to a file or to the train command). Note that if you're writing to stdout, no additional logging info is printed. |
--lang, -l |
Optional code of the language to use. Defaults to "en". |
--pipeline, -p |
Comma-separated list of trainable pipeline components to include. Defaults to "tagger,parser,ner". |
--optimize, -o |
"efficiency" or "accuracy". Whether to optimize for efficiency (faster inference, smaller model, lower memory consumption) or higher accuracy (potentially larger and slower model). This will impact the choice of architecture, pretrained weights and related hyperparameters. Defaults to "efficiency". |
--gpu, -G |
Whether the model can run on GPU. This will impact the choice of architecture, pretrained weights and related hyperparameters. |
--pretraining, -pt |
Include config for pretraining (with spacy pretrain). Defaults to False. |
--force, -f |
Force overwriting the output file if it already exists. |
--help, -h |
Show help message and available arguments. |
| CREATES | The config file for training. |
init fill-config
Auto-fill a partial config.cfg file file with all
default values, e.g. a config generated with the
quickstart widget. Config files used for training
should always be complete and not contain any hidden defaults or missing values,
so this command helps you create your final training config. In order to find
the available settings and defaults, all functions referenced in the config will
be created, and their signatures are used to find the defaults. If your config
contains a problem that can't be resolved automatically, spaCy will show you a
validation error with more details.
Example
$ python -m spacy init fill-config base.cfg config.cfg --diffExample diff

$ python -m spacy init fill-config [base_path] [output_file] [--diff]
| Name | Description |
|---|---|
base_path |
Path to base config to fill, e.g. generated by the quickstart widget. |
output_file |
Path to output .cfg file. If not set, the config is written to stdout so you can pipe it forward to a file. |
--code, -c |
Path to Python file with additional code to be imported. Allows registering custom functions for new architectures. |
--pretraining, -pt |
Include config for pretraining (with spacy pretrain). Defaults to False. |
--diff, -D |
Print a visual diff highlighting the changes. |
--help, -h |
Show help message and available arguments. |
| CREATES | Complete and auto-filled config file for training. |
init vectors
Convert word vectors for use
with spaCy. Will export an nlp object that you can use in the
[initialize] block of your config to
initialize a model with vectors. See the usage guide on
static vectors for details on
how to use vectors in your model.
This functionality was previously available as part of the command init-model.
$ python -m spacy init vectors [lang] [vectors_loc] [output_dir] [--prune] [--truncate] [--name] [--verbose]
| Name | Description |
|---|---|
lang |
Pipeline language ISO code, e.g. en. |
vectors_loc |
Location of vectors. Should be a file where the first row contains the dimensions of the vectors, followed by a space-separated Word2Vec table. File can be provided in .txt format or as a zipped text file in .zip or .tar.gz format. |
output_dir |
Pipeline output directory. Will be created if it doesn't exist. |
--truncate, -t |
Number of vectors to truncate to when reading in vectors file. Defaults to 0 for no truncation. |
--prune, -p |
Number of vectors to prune the vocabulary to. Defaults to -1 for no pruning. |
--name, -n |
Name to assign to the word vectors in the meta.json, e.g. en_core_web_md.vectors. |
--verbose, -V |
Print additional information and explanations. |
--help, -h |
Show help message and available arguments. |
| CREATES | A spaCy pipeline directory containing the vocab and vectors. |
init labels
Generate JSON files for the labels in the data. This helps speed up the training
process, since spaCy won't have to preprocess the data to extract the labels.
After generating the labels, you can provide them to components that accept a
labels argument on initialization via the
[initialize] block of your config.
Example config
[initialize.components.ner] [initialize.components.ner.labels] @readers = "spacy.read_labels.v1" path = "corpus/labels/ner.json
$ python -m spacy init labels [config_path] [output_path] [--code] [--verbose] [--gpu-id] [overrides]
| Name | Description |
|---|---|
config_path |
Path to training config file containing all settings and hyperparameters. If -, the data will be read from stdin. |
output_path |
Output directory for the label files. Will create one JSON file per component. |
--code, -c |
Path to Python file with additional code to be imported. Allows registering custom functions for new architectures. |
--verbose, -V |
Show more detailed messages for debugging purposes. |
--gpu-id, -g |
GPU ID or -1 for CPU. Defaults to -1. |
--help, -h |
Show help message and available arguments. |
| overrides | Config parameters to override. Should be options starting with -- that correspond to the config section and value to override, e.g. --paths.train ./train.spacy. |
| CREATES | The label files. |
convert
Convert files into spaCy's
binary training data format, a serialized
DocBin, for use with the train command and other experiment
management functions. The converter can be specified on the command line, or
chosen based on the file extension of the input file.
$ python -m spacy convert [input_file] [output_dir] [--converter] [--file-type] [--n-sents] [--seg-sents] [--base] [--morphology] [--merge-subtokens] [--ner-map] [--lang]
| Name | Description |
|---|---|
input_file |
Input file. |
output_dir |
Output directory for converted file. Defaults to "-", meaning data will be written to stdout. |
--converter, -c 2 |
Name of converter to use (see below). |
--file-type, -t 2.1 |
Type of file to create. Either spacy (default) for binary DocBin data or json for v2.x JSON format. |
--n-sents, -n |
Number of sentences per document. Supported for: conll, conllu, iob, ner |
--seg-sents, -s 2.2 |
Segment sentences. Supported for: conll, ner |
--base, -b |
Trained spaCy pipeline for sentence segmentation to use as base (for --seg-sents). |
--morphology, -m |
Enable appending morphology to tags. Supported for: conllu |
--ner-map, -nm |
NER tag mapping (as JSON-encoded dict of entity types). Supported for: conllu |
--lang, -l 2.1 |
Language code (if tokenizer required). |
--help, -h |
Show help message and available arguments. |
| CREATES | Binary DocBin training data that can be used with spacy train. |
Converters
| ID | Description |
|---|---|
auto |
Automatically pick converter based on file extension and file content (default). |
json |
JSON-formatted training data used in spaCy v2.x. |
conllu |
Universal Dependencies .conllu format. |
ner / conll |
NER with IOB/IOB2/BILUO tags, one token per line with columns separated by whitespace. The first column is the token and the final column is the NER tag. Sentences are separated by blank lines and documents are separated by the line -DOCSTART- -X- O O. Supports CoNLL 2003 NER format. See sample data. |
iob |
NER with IOB/IOB2/BILUO tags, one sentence per line with tokens separated by whitespace and annotation separated by |, either word|B-ENTorword|POS|B-ENT. See sample data. |
debug
The spacy debug CLI includes helpful commands for debugging and profiling your
configs, data and implementations.
debug config
Debug a config.cfg file and show validation errors.
The command will create all objects in the tree and validate them. Note that
some config validation errors are blocking and will prevent the rest of the
config from being resolved. This means that you may not see all validation
errors at once and some issues are only shown once previous errors have been
fixed. To auto-fill a partial config and save the result, you can use the
init fill-config command.
$ python -m spacy debug config [config_path] [--code] [--show-functions] [--show-variables] [overrides]
Example
$ python -m spacy debug config config.cfg
✘ Config validation error
dropout field required
optimizer field required
optimize extra fields not permitted
{'seed': 0, 'accumulate_gradient': 1, 'dev_corpus': 'corpora.dev', 'train_corpus': 'corpora.train', 'gpu_allocator': None, 'patience': 1600, 'max_epochs': 0, 'max_steps': 20000, 'eval_frequency': 200, 'frozen_components': [], 'optimize': None, 'before_to_disk': None, 'batcher': {'@batchers': 'spacy.batch_by_words.v1', 'discard_oversize': False, 'tolerance': 0.2, 'get_length': None, 'size': {'@schedules': 'compounding.v1', 'start': 100, 'stop': 1000, 'compound': 1.001, 't': 0.0}}, 'logger': {'@loggers': 'spacy.ConsoleLogger.v1', 'progress_bar': False}, 'score_weights': {'tag_acc': 0.5, 'dep_uas': 0.25, 'dep_las': 0.25, 'sents_f': 0.0}}
If your config contains missing values, you can run the 'init fill-config'
command to fill in all the defaults, if possible:
python -m spacy init fill-config tmp/starter-config_invalid.cfg tmp/starter-config_invalid.cfg
$ python -m spacy debug config ./config.cfg --show-functions --show-variables
============================= Config validation =============================
✔ Config is valid
=============================== Variables (6) ===============================
Variable Value
----------------------------------------- ----------------------------------
${components.tok2vec.model.encode.width} 96
${paths.dev} 'hello'
${paths.init_tok2vec} None
${paths.raw} None
${paths.train} ''
${system.seed} 0
========================= Registered functions (17) =========================
ℹ [nlp.tokenizer]
Registry @tokenizers
Name spacy.Tokenizer.v1
Module spacy.language
File /path/to/spacy/language.py (line 64)
ℹ [components.ner.model]
Registry @architectures
Name spacy.TransitionBasedParser.v1
Module spacy.ml.models.parser
File /path/to/spacy/ml/models/parser.py (line 11)
ℹ [components.ner.model.tok2vec]
Registry @architectures
Name spacy.Tok2VecListener.v1
Module spacy.ml.models.tok2vec
File /path/to/spacy/ml/models/tok2vec.py (line 16)
ℹ [components.parser.model]
Registry @architectures
Name spacy.TransitionBasedParser.v1
Module spacy.ml.models.parser
File /path/to/spacy/ml/models/parser.py (line 11)
ℹ [components.parser.model.tok2vec]
Registry @architectures
Name spacy.Tok2VecListener.v1
Module spacy.ml.models.tok2vec
File /path/to/spacy/ml/models/tok2vec.py (line 16)
ℹ [components.tagger.model]
Registry @architectures
Name spacy.Tagger.v1
Module spacy.ml.models.tagger
File /path/to/spacy/ml/models/tagger.py (line 9)
ℹ [components.tagger.model.tok2vec]
Registry @architectures
Name spacy.Tok2VecListener.v1
Module spacy.ml.models.tok2vec
File /path/to/spacy/ml/models/tok2vec.py (line 16)
ℹ [components.tok2vec.model]
Registry @architectures
Name spacy.Tok2Vec.v1
Module spacy.ml.models.tok2vec
File /path/to/spacy/ml/models/tok2vec.py (line 72)
ℹ [components.tok2vec.model.embed]
Registry @architectures
Name spacy.MultiHashEmbed.v1
Module spacy.ml.models.tok2vec
File /path/to/spacy/ml/models/tok2vec.py (line 93)
ℹ [components.tok2vec.model.encode]
Registry @architectures
Name spacy.MaxoutWindowEncoder.v1
Module spacy.ml.models.tok2vec
File /path/to/spacy/ml/models/tok2vec.py (line 207)
ℹ [corpora.dev]
Registry @readers
Name spacy.Corpus.v1
Module spacy.training.corpus
File /path/to/spacy/training/corpus.py (line 18)
ℹ [corpora.train]
Registry @readers
Name spacy.Corpus.v1
Module spacy.training.corpus
File /path/to/spacy/training/corpus.py (line 18)
ℹ [training.logger]
Registry @loggers
Name spacy.ConsoleLogger.v1
Module spacy.training.loggers
File /path/to/spacy/training/loggers.py (line 8)
ℹ [training.batcher]
Registry @batchers
Name spacy.batch_by_words.v1
Module spacy.training.batchers
File /path/to/spacy/training/batchers.py (line 49)
ℹ [training.batcher.size]
Registry @schedules
Name compounding.v1
Module thinc.schedules
File /path/to/thinc/thinc/schedules.py (line 43)
ℹ [training.optimizer]
Registry @optimizers
Name Adam.v1
Module thinc.optimizers
File /path/to/thinc/thinc/optimizers.py (line 58)
ℹ [training.optimizer.learn_rate]
Registry @schedules
Name warmup_linear.v1
Module thinc.schedules
File /path/to/thinc/thinc/schedules.py (line 91)
| Name | Description |
|---|---|
config_path |
Path to training config file containing all settings and hyperparameters. If -, the data will be read from stdin. |
--code, -c |
Path to Python file with additional code to be imported. Allows registering custom functions for new architectures. |
--show-functions, -F |
Show an overview of all registered function blocks used in the config and where those functions come from, including the module name, Python file and line number. |
--show-variables, -V |
Show an overview of all variables referenced in the config, e.g. ${paths.train} and their values that will be used. This also reflects any config overrides provided on the CLI, e.g. --paths.train /path. |
--help, -h |
Show help message and available arguments. |
| overrides | Config parameters to override. Should be options starting with -- that correspond to the config section and value to override, e.g. --paths.train ./train.spacy. |
| PRINTS | Config validation errors, if available. |
debug data
Analyze, debug and validate your training and development data. Get useful stats, and find problems like invalid entity annotations, cyclic dependencies, low data labels and more.
The debug data command is now available as a subcommand of spacy debug. It
takes the same arguments as train and reads settings off the
config.cfg file and optional
overrides on the CLI.
$ python -m spacy debug data [config_path] [--code] [--ignore-warnings] [--verbose] [--no-format] [overrides]
Example
$ python -m spacy debug data ./config.cfg
=========================== Data format validation ===========================
✔ Corpus is loadable
✔ Pipeline can be initialized with data
=============================== Training stats ===============================
Training pipeline: tagger, parser, ner
Starting with blank model 'en'
18127 training docs
2939 evaluation docs
⚠ 34 training examples also in evaluation data
============================== Vocab & Vectors ==============================
ℹ 2083156 total words in the data (56962 unique)
⚠ 13020 misaligned tokens in the training data
⚠ 2423 misaligned tokens in the dev data
10 most common words: 'the' (98429), ',' (91756), '.' (87073), 'to' (50058),
'of' (49559), 'and' (44416), 'a' (34010), 'in' (31424), 'that' (22792), 'is'
(18952)
ℹ No word vectors present in the model
========================== Named Entity Recognition ==========================
ℹ 18 new labels, 0 existing labels
528978 missing values (tokens with '-' label)
New: 'ORG' (23860), 'PERSON' (21395), 'GPE' (21193), 'DATE' (18080), 'CARDINAL'
(10490), 'NORP' (9033), 'MONEY' (5164), 'PERCENT' (3761), 'ORDINAL' (2122),
'LOC' (2113), 'TIME' (1616), 'WORK_OF_ART' (1229), 'QUANTITY' (1150), 'FAC'
(1134), 'EVENT' (974), 'PRODUCT' (935), 'LAW' (444), 'LANGUAGE' (338)
✔ Good amount of examples for all labels
✔ Examples without occurences available for all labels
✔ No entities consisting of or starting/ending with whitespace
=========================== Part-of-speech Tagging ===========================
ℹ 49 labels in data
'NN' (266331), 'IN' (227365), 'DT' (185600), 'NNP' (164404), 'JJ' (119830),
'NNS' (110957), '.' (101482), ',' (92476), 'RB' (90090), 'PRP' (90081), 'VB'
(74538), 'VBD' (68199), 'CC' (62862), 'VBZ' (50712), 'VBP' (43420), 'VBN'
(42193), 'CD' (40326), 'VBG' (34764), 'TO' (31085), 'MD' (25863), 'PRP$'
(23335), 'HYPH' (13833), 'POS' (13427), 'UH' (13322), 'WP' (10423), 'WDT'
(9850), 'RP' (8230), 'WRB' (8201), ':' (8168), '''' (7392), '``' (6984), 'NNPS'
(5817), 'JJR' (5689), '$' (3710), 'EX' (3465), 'JJS' (3118), 'RBR' (2872),
'-RRB-' (2825), '-LRB-' (2788), 'PDT' (2078), 'XX' (1316), 'RBS' (1142), 'FW'
(794), 'NFP' (557), 'SYM' (440), 'WP$' (294), 'LS' (293), 'ADD' (191), 'AFX'
(24)
============================= Dependency Parsing =============================
ℹ Found 111703 sentences with an average length of 18.6 words.
ℹ Found 2251 nonprojective train sentences
ℹ Found 303 nonprojective dev sentences
ℹ 47 labels in train data
ℹ 211 labels in projectivized train data
'punct' (236796), 'prep' (188853), 'pobj' (182533), 'det' (172674), 'nsubj'
(169481), 'compound' (116142), 'ROOT' (111697), 'amod' (107945), 'dobj' (93540),
'aux' (86802), 'advmod' (86197), 'cc' (62679), 'conj' (59575), 'poss' (36449),
'ccomp' (36343), 'advcl' (29017), 'mark' (27990), 'nummod' (24582), 'relcl'
(21359), 'xcomp' (21081), 'attr' (18347), 'npadvmod' (17740), 'acomp' (17204),
'auxpass' (15639), 'appos' (15368), 'neg' (15266), 'nsubjpass' (13922), 'case'
(13408), 'acl' (12574), 'pcomp' (10340), 'nmod' (9736), 'intj' (9285), 'prt'
(8196), 'quantmod' (7403), 'dep' (4300), 'dative' (4091), 'agent' (3908), 'expl'
(3456), 'parataxis' (3099), 'oprd' (2326), 'predet' (1946), 'csubj' (1494),
'subtok' (1147), 'preconj' (692), 'meta' (469), 'csubjpass' (64), 'iobj' (1)
⚠ Low number of examples for label 'iobj' (1)
⚠ Low number of examples for 130 labels in the projectivized dependency
trees used for training. You may want to projectivize labels such as punct
before training in order to improve parser performance.
⚠ Projectivized labels with low numbers of examples: appos||attr: 12
advmod||dobj: 13 prep||ccomp: 12 nsubjpass||ccomp: 15 pcomp||prep: 14
amod||dobj: 9 attr||xcomp: 14 nmod||nsubj: 17 prep||advcl: 2 prep||prep: 5
nsubj||conj: 12 advcl||advmod: 18 ccomp||advmod: 11 ccomp||pcomp: 5 acl||pobj:
10 npadvmod||acomp: 7 dobj||pcomp: 14 nsubjpass||pcomp: 1 nmod||pobj: 8
amod||attr: 6 nmod||dobj: 12 aux||conj: 1 neg||conj: 1 dative||xcomp: 11
pobj||dative: 3 xcomp||acomp: 19 advcl||pobj: 2 nsubj||advcl: 2 csubj||ccomp: 1
advcl||acl: 1 relcl||nmod: 2 dobj||advcl: 10 advmod||advcl: 3 nmod||nsubjpass: 6
amod||pobj: 5 cc||neg: 1 attr||ccomp: 16 advcl||xcomp: 3 nmod||attr: 4
advcl||nsubjpass: 5 advcl||ccomp: 4 ccomp||conj: 1 punct||acl: 1 meta||acl: 1
parataxis||acl: 1 prep||acl: 1 amod||nsubj: 7 ccomp||ccomp: 3 acomp||xcomp: 5
dobj||acl: 5 prep||oprd: 6 advmod||acl: 2 dative||advcl: 1 pobj||agent: 5
xcomp||amod: 1 dep||advcl: 1 prep||amod: 8 relcl||compound: 1 advcl||csubj: 3
npadvmod||conj: 2 npadvmod||xcomp: 4 advmod||nsubj: 3 ccomp||amod: 7
advcl||conj: 1 nmod||conj: 2 advmod||nsubjpass: 2 dep||xcomp: 2 appos||ccomp: 1
advmod||dep: 1 advmod||advmod: 5 aux||xcomp: 8 dep||advmod: 1 dative||ccomp: 2
prep||dep: 1 conj||conj: 1 dep||ccomp: 4 cc||ROOT: 1 prep||ROOT: 1 nsubj||pcomp:
3 advmod||prep: 2 relcl||dative: 1 acl||conj: 1 advcl||attr: 4 prep||npadvmod: 1
nsubjpass||xcomp: 1 neg||advmod: 1 xcomp||oprd: 1 advcl||advcl: 1 dobj||dep: 3
nsubjpass||parataxis: 1 attr||pcomp: 1 ccomp||parataxis: 1 advmod||attr: 1
nmod||oprd: 1 appos||nmod: 2 advmod||relcl: 1 appos||npadvmod: 1 appos||conj: 1
prep||expl: 1 nsubjpass||conj: 1 punct||pobj: 1 cc||pobj: 1 conj||pobj: 1
punct||conj: 1 ccomp||dep: 1 oprd||xcomp: 3 ccomp||xcomp: 1 ccomp||nsubj: 1
nmod||dep: 1 xcomp||ccomp: 1 acomp||advcl: 1 intj||advmod: 1 advmod||acomp: 2
relcl||oprd: 1 advmod||prt: 1 advmod||pobj: 1 appos||nummod: 1 relcl||npadvmod:
3 mark||advcl: 1 aux||ccomp: 1 amod||nsubjpass: 1 npadvmod||advmod: 1 conj||dep:
1 nummod||pobj: 1 amod||npadvmod: 1 intj||pobj: 1 nummod||npadvmod: 1
xcomp||xcomp: 1 aux||dep: 1 advcl||relcl: 1
⚠ The following labels were found only in the train data: xcomp||amod,
advcl||relcl, prep||nsubjpass, acl||nsubj, nsubjpass||conj, xcomp||oprd,
advmod||conj, advmod||advmod, iobj, advmod||nsubjpass, dobj||conj, ccomp||amod,
meta||acl, xcomp||xcomp, prep||attr, prep||ccomp, advcl||acomp, acl||dobj,
advcl||advcl, pobj||agent, prep||advcl, nsubjpass||xcomp, prep||dep,
acomp||xcomp, aux||ccomp, ccomp||dep, conj||dep, relcl||compound,
nsubjpass||ccomp, nmod||dobj, advmod||advcl, advmod||acl, dobj||advcl,
dative||xcomp, prep||nsubj, ccomp||ccomp, nsubj||ccomp, xcomp||acomp,
prep||acomp, dep||advmod, acl||pobj, appos||dobj, npadvmod||acomp, cc||ROOT,
relcl||nsubj, nmod||pobj, acl||nsubjpass, ccomp||advmod, pcomp||prep,
amod||dobj, advmod||attr, advcl||csubj, appos||attr, dobj||pcomp, prep||ROOT,
relcl||pobj, advmod||pobj, amod||nsubj, ccomp||xcomp, prep||oprd,
npadvmod||advmod, appos||nummod, advcl||pobj, neg||advmod, acl||attr,
appos||nsubjpass, csubj||ccomp, amod||nsubjpass, intj||pobj, dep||advcl,
cc||neg, xcomp||ccomp, dative||ccomp, nmod||oprd, pobj||dative, prep||dobj,
dep||ccomp, relcl||attr, ccomp||nsubj, advcl||xcomp, nmod||dep, advcl||advmod,
ccomp||conj, pobj||prep, advmod||acomp, advmod||relcl, attr||pcomp,
ccomp||parataxis, oprd||xcomp, intj||advmod, nmod||nsubjpass, prep||npadvmod,
parataxis||acl, prep||pobj, advcl||dobj, amod||pobj, prep||acl, conj||pobj,
advmod||dep, punct||pobj, ccomp||acomp, acomp||advcl, nummod||npadvmod,
dobj||dep, npadvmod||xcomp, advcl||conj, relcl||npadvmod, punct||acl,
relcl||dobj, dobj||xcomp, nsubjpass||parataxis, dative||advcl, relcl||nmod,
advcl||ccomp, appos||npadvmod, ccomp||pcomp, prep||amod, mark||advcl,
prep||advmod, prep||xcomp, appos||nsubj, attr||ccomp, advmod||prt, dobj||ccomp,
aux||conj, advcl||nsubj, conj||conj, advmod||ccomp, advcl||nsubjpass,
attr||xcomp, nmod||conj, npadvmod||conj, relcl||dative, prep||expl,
nsubjpass||pcomp, advmod||xcomp, advmod||dobj, appos||pobj, nsubj||conj,
relcl||nsubjpass, advcl||attr, appos||ccomp, advmod||prep, prep||conj,
nmod||attr, punct||conj, neg||conj, dep||xcomp, aux||xcomp, dobj||acl,
nummod||pobj, amod||npadvmod, nsubj||pcomp, advcl||acl, appos||nmod,
relcl||oprd, prep||prep, cc||pobj, nmod||nsubj, amod||attr, aux||dep,
appos||conj, advmod||nsubj, nsubj||advcl, acl||conj
To train a parser, your data should include at least 20 instances of each label.
⚠ Multiple root labels (ROOT, nsubj, aux, npadvmod, prep) found in
training data. spaCy's parser uses a single root label ROOT so this distinction
will not be available.
================================== Summary ==================================
✔ 5 checks passed
⚠ 8 warnings
| Name | Description |
|---|---|
config_path |
Path to training config file containing all settings and hyperparameters. If -, the data will be read from stdin. |
--code, -c |
Path to Python file with additional code to be imported. Allows registering custom functions for new architectures. |
--ignore-warnings, -IW |
Ignore warnings, only show stats and errors. |
--verbose, -V |
Print additional information and explanations. |
--no-format, -NF |
Don't pretty-print the results. Use this if you want to write to a file. |
--help, -h |
Show help message and available arguments. |
| overrides | Config parameters to override. Should be options starting with -- that correspond to the config section and value to override, e.g. --paths.train ./train.spacy. |
| PRINTS | Debugging information. |
debug profile
Profile which functions take the most time in a spaCy pipeline. Input should be
formatted as one JSON object per line with a key "text". It can either be
provided as a JSONL file, or be read from sys.sytdin. If no input file is
specified, the IMDB dataset is loaded via
ml_datasets.
The profile command is now available as a subcommand of spacy debug.
$ python -m spacy debug profile [model] [inputs] [--n-texts]
| Name | Description |
|---|---|
model |
A loadable spaCy pipeline (package name or path). |
inputs |
Path to input file, or - for standard input. |
--n-texts, -n |
Maximum number of texts to use if available. Defaults to 10000. |
--help, -h |
Show help message and available arguments. |
| PRINTS | Profiling information for the pipeline. |
debug model
Debug a Thinc Model by running it on a
sample text and checking how it updates its internal weights and parameters.
$ python -m spacy debug model [config_path] [component] [--layers] [--dimensions] [--parameters] [--gradients] [--attributes] [--print-step0] [--print-step1] [--print-step2] [--print-step3] [--gpu-id]
In this example log, we just print the name of each layer after creation of the model ("Step 0"), which helps us to understand the internal structure of the Neural Network, and to focus on specific layers that we want to inspect further (see next example).
$ python -m spacy debug model ./config.cfg tagger -P0
ℹ Using CPU
ℹ Fixing random seed: 0
ℹ Analysing model with ID 62
========================== STEP 0 - before training ==========================
ℹ Layer 0: model ID 62:
'extract_features>>list2ragged>>with_array-ints-getitem>>hashembed|ints-getitem>>hashembed|ints-getitem>>hashembed|ints-getitem>>hashembed>>with_array-maxout>>layernorm>>dropout>>ragged2list>>with_array-residual>>residual>>residual>>residual>>with_array-softmax'
ℹ Layer 1: model ID 59:
'extract_features>>list2ragged>>with_array-ints-getitem>>hashembed|ints-getitem>>hashembed|ints-getitem>>hashembed|ints-getitem>>hashembed>>with_array-maxout>>layernorm>>dropout>>ragged2list>>with_array-residual>>residual>>residual>>residual'
ℹ Layer 2: model ID 61: 'with_array-softmax'
ℹ Layer 3: model ID 24:
'extract_features>>list2ragged>>with_array-ints-getitem>>hashembed|ints-getitem>>hashembed|ints-getitem>>hashembed|ints-getitem>>hashembed>>with_array-maxout>>layernorm>>dropout>>ragged2list'
ℹ Layer 4: model ID 58: 'with_array-residual>>residual>>residual>>residual'
ℹ Layer 5: model ID 60: 'softmax'
ℹ Layer 6: model ID 13: 'extract_features'
ℹ Layer 7: model ID 14: 'list2ragged'
ℹ Layer 8: model ID 16:
'with_array-ints-getitem>>hashembed|ints-getitem>>hashembed|ints-getitem>>hashembed|ints-getitem>>hashembed'
ℹ Layer 9: model ID 22: 'with_array-maxout>>layernorm>>dropout'
ℹ Layer 10: model ID 23: 'ragged2list'
ℹ Layer 11: model ID 57: 'residual>>residual>>residual>>residual'
ℹ Layer 12: model ID 15:
'ints-getitem>>hashembed|ints-getitem>>hashembed|ints-getitem>>hashembed|ints-getitem>>hashembed'
ℹ Layer 13: model ID 21: 'maxout>>layernorm>>dropout'
ℹ Layer 14: model ID 32: 'residual'
ℹ Layer 15: model ID 40: 'residual'
ℹ Layer 16: model ID 48: 'residual'
ℹ Layer 17: model ID 56: 'residual'
ℹ Layer 18: model ID 3: 'ints-getitem>>hashembed'
ℹ Layer 19: model ID 6: 'ints-getitem>>hashembed'
ℹ Layer 20: model ID 9: 'ints-getitem>>hashembed'
...
In this example log, we see how initialization of the model (Step 1) propagates
the correct values for the nI (input) and nO (output) dimensions of the
various layers. In the softmax layer, this step also defines the W matrix as
an all-zero matrix determined by the nO and nI dimensions. After a first
training step (Step 2), this matrix has clearly updated its values through the
training feedback loop.
$ python -m spacy debug model ./config.cfg tagger -l "5,15" -DIM -PAR -P0 -P1 -P2
ℹ Using CPU
ℹ Fixing random seed: 0
ℹ Analysing model with ID 62
========================= STEP 0 - before training =========================
ℹ Layer 5: model ID 60: 'softmax'
ℹ - dim nO: None
ℹ - dim nI: 96
ℹ - param W: None
ℹ - param b: None
ℹ Layer 15: model ID 40: 'residual'
ℹ - dim nO: None
ℹ - dim nI: None
======================= STEP 1 - after initialization =======================
ℹ Layer 5: model ID 60: 'softmax'
ℹ - dim nO: 4
ℹ - dim nI: 96
ℹ - param W: (4, 96) - sample: [0. 0. 0. 0. 0.]
ℹ - param b: (4,) - sample: [0. 0. 0. 0.]
ℹ Layer 15: model ID 40: 'residual'
ℹ - dim nO: 96
ℹ - dim nI: None
========================== STEP 2 - after training ==========================
ℹ Layer 5: model ID 60: 'softmax'
ℹ - dim nO: 4
ℹ - dim nI: 96
ℹ - param W: (4, 96) - sample: [ 0.00283958 -0.00294119 0.00268396 -0.00296219
-0.00297141]
ℹ - param b: (4,) - sample: [0.00300002 0.00300002 0.00300002 0.00300002]
ℹ Layer 15: model ID 40: 'residual'
ℹ - dim nO: 96
ℹ - dim nI: None
| Name | Description |
|---|---|
config_path |
Path to training config file containing all settings and hyperparameters. If -, the data will be read from stdin. |
component |
Name of the pipeline component of which the model should be analyzed. |
--layers, -l |
Comma-separated names of layer IDs to print. |
--dimensions, -DIM |
Show dimensions of each layer. |
--parameters, -PAR |
Show parameters of each layer. |
--gradients, -GRAD |
Show gradients of each layer. |
--attributes, -ATTR |
Show attributes of each layer. |
--print-step0, -P0 |
Print model before training. |
--print-step1, -P1 |
Print model after initialization. |
--print-step2, -P2 |
Print model after training. |
--print-step3, -P3 |
Print final predictions. |
--gpu-id, -g |
GPU ID or -1 for CPU. Defaults to -1. |
--help, -h |
Show help message and available arguments. |
| overrides | Config parameters to override. Should be options starting with -- that correspond to the config section and value to override, e.g. --paths.train ./train.spacy. |
| PRINTS | Debugging information. |
train
Train a pipeline. Expects data in spaCy's
binary format and a
config file with all settings and hyperparameters.
Will save out the best model from all epochs, as well as the final pipeline. The
--code argument can be used to provide a Python file that's imported before
the training process starts. This lets you register
custom functions and architectures and refer
to them in your config, all while still using spaCy's built-in train workflow.
If you need to manage complex multi-step training workflows, check out the new
spaCy projects.
The train command doesn't take a long list of command-line arguments anymore
and instead expects a single config.cfg file
containing all settings for the pipeline, training process and hyperparameters.
Config values can be overwritten on the CLI
if needed. For example, --paths.train ./train.spacy sets the variable train
in the section [paths].
Example
$ python -m spacy train config.cfg --output ./output --paths.train ./train --paths.dev ./dev
$ python -m spacy train [config_path] [--output] [--code] [--verbose] [--gpu-id] [overrides]
| Name | Description |
|---|---|
config_path |
Path to training config file containing all settings and hyperparameters. If -, the data will be read from stdin. |
--output, -o |
Directory to store trained pipeline in. Will be created if it doesn't exist. |
--code, -c |
Path to Python file with additional code to be imported. Allows registering custom functions for new architectures. |
--verbose, -V |
Show more detailed messages during training. |
--gpu-id, -g |
GPU ID or -1 for CPU. Defaults to -1. |
--help, -h |
Show help message and available arguments. |
| overrides | Config parameters to override. Should be options starting with -- that correspond to the config section and value to override, e.g. --paths.train ./train.spacy. |
| CREATES | The final trained pipeline and the best trained pipeline. |
pretrain
Pretrain the "token to vector" (Tok2vec) layer of pipeline
components on raw text, using an approximate language-modeling objective.
Specifically, we load pretrained vectors, and train a component like a CNN,
BiLSTM, etc to predict vectors which match the pretrained ones. The weights are
saved to a directory after each epoch. You can then include a path to one of
these pretrained weights files in your
training config as the init_tok2vec setting when you
train your pipeline. This technique may be especially helpful if you have little
labelled data. See the usage docs on
pretraining for more info. To read
the raw text, a JsonlCorpus is typically used.
As of spaCy v3.0, the pretrain command takes the same
config file as the train command. This ensures that
settings are consistent between pretraining and training. Settings for
pretraining can be defined in the [pretraining] block of the config file and
auto-generated by setting --pretraining on
init fill-config. Also see the
data format for details.
Example
$ python -m spacy pretrain config.cfg ./output_pretrain --paths.raw_text ./data.jsonl
$ python -m spacy pretrain [config_path] [output_dir] [--code] [--resume-path] [--epoch-resume] [--gpu-id] [overrides]
| Name | Description |
|---|---|
config_path |
Path to training config file containing all settings and hyperparameters. If -, the data will be read from stdin. |
output_dir |
Directory to save binary weights to on each epoch. |
--code, -c |
Path to Python file with additional code to be imported. Allows registering custom functions for new architectures. |
--resume-path, -r |
Path to pretrained weights from which to resume pretraining. |
--epoch-resume, -er |
The epoch to resume counting from when using --resume-path. Prevents unintended overwriting of existing weight files. |
--gpu-id, -g |
GPU ID or -1 for CPU. Defaults to -1. |
--help, -h |
Show help message and available arguments. |
| overrides | Config parameters to override. Should be options starting with -- that correspond to the config section and value to override, e.g. --training.dropout 0.2. |
| CREATES | The pretrained weights that can be used to initialize spacy train. |
evaluate
Evaluate a trained pipeline. Expects a loadable spaCy pipeline (package name or
path) and evaluation data in the
binary .spacy format. The
--gold-preproc option sets up the evaluation examples with gold-standard
sentences and tokens for the predictions. Gold preprocessing helps the
annotations align to the tokenization, and may result in sequences of more
consistent length. However, it may reduce runtime accuracy due to train/test
skew. To render a sample of dependency parses in a HTML file using the
displaCy visualizations, set as output directory as the
--displacy-path argument.
$ python -m spacy evaluate [model] [data_path] [--output] [--code] [--gold-preproc] [--gpu-id] [--displacy-path] [--displacy-limit]
| Name | Description |
|---|---|
model |
Pipeline to evaluate. Can be a package or a path to a data directory. |
data_path |
Location of evaluation data in spaCy's binary format. |
--output, -o |
Output JSON file for metrics. If not set, no metrics will be exported. |
--code, -c 3 |
Path to Python file with additional code to be imported. Allows registering custom functions for new architectures. |
--gold-preproc, -G |
Use gold preprocessing. |
--gpu-id, -g |
GPU to use, if any. Defaults to -1 for CPU. |
--displacy-path, -dp |
Directory to output rendered parses as HTML. If not set, no visualizations will be generated. |
--displacy-limit, -dl |
Number of parses to generate per file. Defaults to 25. Keep in mind that a significantly higher number might cause the .html files to render slowly. |
--help, -h |
Show help message and available arguments. |
| CREATES | Training results and optional metrics and visualizations. |
assemble
Assemble a pipeline from a config file without additional training. Expects a
config file with all settings and hyperparameters.
The --code argument can be used to import a Python file that lets you register
custom functions and refer to them in your
config.
Example
$ python -m spacy assemble config.cfg ./output
$ python -m spacy assemble [config_path] [output_dir] [--code] [--verbose] [overrides]
| Name | Description |
|---|---|
config_path |
Path to the config file containing all settings and hyperparameters. If -, the data will be read from stdin. |
output_dir |
Directory to store the final pipeline in. Will be created if it doesn't exist. |
--code, -c |
Path to Python file with additional code to be imported. Allows registering custom functions. |
--verbose, -V |
Show more detailed messages during processing. |
--help, -h |
Show help message and available arguments. |
| overrides | Config parameters to override. Should be options starting with -- that correspond to the config section and value to override, e.g. --paths.data ./data. |
| CREATES | The final assembled pipeline. |
package
Generate an installable Python package from
an existing pipeline data directory. All data files are copied over. If
additional code files are provided (e.g. Python files containing custom
registered functions like
pipeline components), they are
copied into the package and imported in the __init__.py. If the path to a
meta.json is supplied, or a meta.json is found in
the input directory, this file is used. Otherwise, the data can be entered
directly from the command line. spaCy will then create a build artifact that you
can distribute and install with pip install. As of v3.1, the package command
will also create a formatted README.md based on the pipeline information
defined in the meta.json. If a README.md is already present in the source
directory, it will be used instead.
The spacy package command now also builds the .tar.gz archive automatically,
so you don't have to run python setup.py sdist separately anymore. To disable
this, you can set --build none. You can also choose to build a binary wheel
(which installs more efficiently) by setting --build wheel, or to build both
the sdist and wheel by setting --build sdist,wheel.
$ python -m spacy package [input_dir] [output_dir] [--code] [--meta-path] [--create-meta] [--build] [--name] [--version] [--force]
Example
$ python -m spacy package /input /output $ cd /output/en_pipeline-0.0.0 $ pip install dist/en_pipeline-0.0.0.tar.gz
| Name | Description |
|---|---|
input_dir |
Path to directory containing pipeline data. |
output_dir |
Directory to create package folder in. |
--code, -c 3 |
Comma-separated paths to Python files to be included in the package and imported in its __init__.py. This allows including registering functions and custom components. |
--meta-path, -m 2 |
Path to meta.json file (optional). |
--create-meta, -C 2 |
Create a meta.json file on the command line, even if one already exists in the directory. If an existing file is found, its entries will be shown as the defaults in the command line prompt. |
--build, -b 3 |
Comma-separated artifact formats to build. Can be sdist (for a .tar.gz archive) and/or wheel (for a binary .whl file), or none if you want to run this step manually. The generated artifacts can be installed by pip install. Defaults to sdist. |
--name, -n 3 |
Package name to override in meta. |
--version, -v 3 |
Package version to override in meta. Useful when training new versions, as it doesn't require editing the meta template. |
--force, -f |
Force overwriting of existing folder in output directory. |
--help, -h |
Show help message and available arguments. |
| CREATES | A Python package containing the spaCy pipeline. |
project
The spacy project CLI includes subcommands for working with
spaCy projects, end-to-end workflows for building and
deploying custom spaCy pipelines.
project clone
Clone a project template from a Git repository. Calls into git under the hood
and can use the sparse checkout feature if available, so you're only downloading
what you need. By default, spaCy's
project templates repo is used, but you
can provide any other repo (public or private) that you have access to using the
--repo option.
$ python -m spacy project clone [name] [dest] [--repo] [--branch] [--sparse]
Example
$ python -m spacy project clone pipelines/ner_wikinerClone from custom repo:
$ python -m spacy project clone template --repo https://github.com/your_org/your_repo
| Name | Description |
|---|---|
name |
The name of the template to clone, relative to the repo. Can be a top-level directory or a subdirectory like dir/template. |
dest |
Where to clone the project. Defaults to current working directory. |
--repo, -r |
The repository to clone from. Can be any public or private Git repo you have access to. |
--branch, -b |
The branch to clone from. Defaults to master. |
--sparse, -S |
Enable sparse checkout to only check out and download what's needed. Requires Git v22.2+. |
--help, -h |
Show help message and available arguments. |
| CREATES | The cloned project directory. |
project assets
Fetch project assets like datasets and pretrained weights. Assets are defined in
the assets section of the project.yml. If a
checksum is provided, the file is only downloaded if no local file with the
same checksum exists and spaCy will show an error if the checksum of the
downloaded file doesn't match. If assets don't specify a url they're
considered "private" and you have to take care of putting them into the
destination directory yourself. If a local path is provided, the asset is copied
into the current project.
$ python -m spacy project assets [project_dir]
Example
$ python -m spacy project assets [--sparse]
| Name | Description |
|---|---|
project_dir |
Path to project directory. Defaults to current working directory. |
--sparse, -S |
Enable sparse checkout to only check out and download what's needed. Requires Git v22.2+. |
--help, -h |
Show help message and available arguments. |
| CREATES | Downloaded or copied assets defined in the project.yml. |
project run
Run a named command or workflow defined in the
project.yml. If a workflow name is specified,
all commands in the workflow are run, in order. If commands define
dependencies or outputs, they will only be
re-run if state has changed. For example, if the input dataset changes, a
preprocessing command that depends on those files will be re-run.
$ python -m spacy project run [subcommand] [project_dir] [--force] [--dry]
Example
$ python -m spacy project run train
| Name | Description |
|---|---|
subcommand |
Name of the command or workflow to run. |
project_dir |
Path to project directory. Defaults to current working directory. |
--force, -F |
Force re-running steps, even if nothing changed. |
--dry, -D |
Perform a dry run and don't execute scripts. |
--help, -h |
Show help message and available arguments. |
| EXECUTES | The command defined in the project.yml. |
project push
Upload all available files or directories listed as in the outputs section of
commands to a remote storage. Outputs are archived and compressed prior to
upload, and addressed in the remote storage using the output's relative path
(URL encoded), a hash of its command string and dependencies, and a hash of its
file contents. This means push should never overwrite a file in your
remote. If all the hashes match, the contents are the same and nothing happens.
If the contents are different, the new version of the file is uploaded. Deleting
obsolete files is left up to you.
Remotes can be defined in the remotes section of the
project.yml. Under the hood, spaCy uses the
smart-open library to
communicate with the remote storages, so you can use any protocol that
smart-open supports, including S3,
Google Cloud Storage, SSH and more, although
you may need to install extra dependencies to use certain protocols.
$ python -m spacy project push [remote] [project_dir]
Example
$ python -m spacy project push my_bucket### project.yml remotes: my_bucket: 's3://my-spacy-bucket'
| Name | Description |
|---|---|
remote |
The name of the remote to upload to. Defaults to "default". |
project_dir |
Path to project directory. Defaults to current working directory. |
--help, -h |
Show help message and available arguments. |
| UPLOADS | All project outputs that exist and are not already stored in the remote. |
project pull
Download all files or directories listed as outputs for commands, unless they
are not already present locally. When searching for files in the remote, pull
won't just look at the output path, but will also consider the command
string and the hashes of the dependencies. For instance, let's say you've
previously pushed a checkpoint to the remote, but now you've changed some
hyper-parameters. Because you've changed the inputs to the command, if you run
pull, you won't retrieve the stale result. If you train your pipeline and push
the outputs to the remote, the outputs will be saved alongside the prior
outputs, so if you change the config back, you'll be able to fetch back the
result.
Remotes can be defined in the remotes section of the
project.yml. Under the hood, spaCy uses the
smart-open library to
communicate with the remote storages, so you can use any protocol that
smart-open supports, including S3,
Google Cloud Storage, SSH and more, although
you may need to install extra dependencies to use certain protocols.
$ python -m spacy project pull [remote] [project_dir]
Example
$ python -m spacy project pull my_bucket### project.yml remotes: my_bucket: 's3://my-spacy-bucket'
| Name | Description |
|---|---|
remote |
The name of the remote to download from. Defaults to "default". |
project_dir |
Path to project directory. Defaults to current working directory. |
--help, -h |
Show help message and available arguments. |
| DOWNLOADS | All project outputs that do not exist locally and can be found in the remote. |
project document
Auto-generate a pretty Markdown-formatted README for your project, based on
its project.yml. Will create sections that
document the available commands, workflows and assets. The auto-generated
content will be placed between two hidden markers, so you can add your own
custom content before or after the auto-generated documentation. When you re-run
the project document command, only the auto-generated part is replaced.
$ python -m spacy project document [project_dir] [--output] [--no-emoji]
Example
$ python -m spacy project document --output README.md
For more examples, see the templates in our
projects repo.
| Name | Description |
|---|---|
project_dir |
Path to project directory. Defaults to current working directory. |
--output, -o |
Path to output file or - for stdout (default). If a file is specified and it already exists and contains auto-generated docs, only the auto-generated docs section is replaced. |
--no-emoji, -NE |
Don't use emoji in the titles. |
| CREATES | The Markdown-formatted project documentation. |
project dvc
Auto-generate Data Version Control (DVC) config file. Calls
dvc run with --no-exec under
the hood to generate the dvc.yaml. A DVC project can only define one pipeline,
so you need to specify one workflow defined in the
project.yml. If no workflow is specified, the
first defined workflow is used. The DVC config will only be updated if the
project.yml changed. For details, see the
DVC integration docs.
This command requires DVC to be installed and initialized in the project
directory, e.g. via dvc init.
You'll also need to add the assets you want to track with
dvc add.
$ python -m spacy project dvc [project_dir] [workflow] [--force] [--verbose]
Example
$ git init $ dvc init $ python -m spacy project dvc all
| Name | Description |
|---|---|
project_dir |
Path to project directory. Defaults to current working directory. |
workflow |
Name of workflow defined in project.yml. Defaults to first workflow if not set. |
--force, -F |
Force-updating config file. |
--verbose, -V |
Print more output generated by DVC. |
--help, -h |
Show help message and available arguments. |
| CREATES | A dvc.yaml file in the project directory, based on the steps defined in the given workflow. |
ray
The spacy ray CLI includes commands for parallel and distributed computing via
Ray.
To use this command, you need the
spacy-ray package installed.
Installing the package will automatically add the ray command to the spaCy
CLI.
ray train
Train a spaCy pipeline using Ray for parallel training. The
command works just like spacy train. For more details and
examples, see the usage guide on
parallel training and the spaCy project
integration.
$ python -m spacy ray train [config_path] [--code] [--output] [--n-workers] [--address] [--gpu-id] [--verbose] [overrides]
Example
$ python -m spacy ray train config.cfg --n-workers 2
| Name | Description |
|---|---|
config_path |
Path to training config file containing all settings and hyperparameters. |
--code, -c |
Path to Python file with additional code to be imported. Allows registering custom functions for new architectures. |
--output, -o |
Directory or remote storage URL for saving trained pipeline. The directory will be created if it doesn't exist. |
--n-workers, -n |
The number of workers. Defaults to 1. |
--address, -a |
Optional address of the Ray cluster. If not set (default), Ray will run locally. |
--gpu-id, -g |
GPU ID or -1 for CPU. Defaults to -1. |
--verbose, -V |
Display more information for debugging purposes. |
--help, -h |
Show help message and available arguments. |
| overrides | Config parameters to override. Should be options starting with -- that correspond to the config section and value to override, e.g. --paths.train ./train.spacy. |
huggingface-hub
The spacy huggingface-cli CLI includes commands for uploading your trained
spaCy pipelines to the Hugging Face Hub.
Installation
$ pip install spacy-huggingface-hub $ huggingface-cli login
To use this command, you need the
spacy-huggingface-hub
package installed. Installing the package will automatically add the
huggingface-hub command to the spaCy CLI.
huggingface-hub push
Push a spaCy pipeline to the Hugging Face Hub. Expects a .whl file packaged
with spacy package and --build wheel. For more details,
see the spaCy project integration.
$ python -m spacy huggingface-hub push [whl_path] [--org] [--msg] [--local-repo] [--verbose]
Example
$ python -m spacy huggingface-hub push en_ner_fashion-0.0.0-py3-none-any.whl
| Name | Description |
|---|---|
whl_path |
The path to the .whl file packaged with spacy package. |
--org, -o |
Optional name of organization to which the pipeline should be uploaded. |
--msg, -m |
Commit message to use for update. Defaults to "Update spaCy pipeline". |
--local-repo, -l |
Local path to the model repository (will be created if it doesn't exist). Defaults to hub in the current working directory. |
--verbose, -V |
Output additional info for debugging, e.g. the full generated hub metadata. |
| UPLOADS | The pipeline to the hub. |